Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
“When we say that our machines can render us irrelevant we are buying into a suicidal ideology that has the dark allure of a martyr operation. … This particular breed of lethal passive despair is one of our period’s major moral vices. … We don’t lack gusto because our life is inherently not worth living, we actually lack conviction and self-esteem because we are lying to ourselves.”
Jonathan Prozzi and I have challenged one another to make a post about improving our websites once a week. Here's mine!
Back in 2008 I started a new blog on Wordpress. It seemed like a good idea! Maybe I would post some useful things and someone would offer me a job! I wanted to allow discussion without the dangers of letting strangers submit data directly to my server, so I set up the JavaScript-based Disqus comments service. I made a few posts per year and it eventually tapered off and I largely forgot about it.
In February 2011 I participated in the Thing-a-Day project on Posterous. It was the first time in a long time that I had published consistently, so when it was announced that Posterous was going away, I worked hard to grab my content and stored it somewhere.
Eventually it was November 2013, Wordpress was "out", static site generators were "in", and I wanted to give Octopress a try. I used Octopress' tools to import all my Wordpress content into Octopress, forgot about adding back the Disqus comments, and posted it all back online. In February 2014, I decided to resurrect my Posterous content, so I created posts for it and got everything looking nice enough.
In 2015 I learned about the IndieWeb, and decided it was time for a new approach to my identity and content online. I set up a new site at https://martymcgui.re/ based on Jekyll (hey! static sites are still "in"!) and got to work adding IndieWeb features.
Well, today I decided to get some of that old content off my other domain and into my official one. Thankfully, with Octopress being based on Jekyll, it was mostly just a matter of copying over the files in the _posts/ folder. A few tweaks to a few posts to make up for newer parsing in Jekyll, my somewhat odd URL structure, etc., and I was good to go!
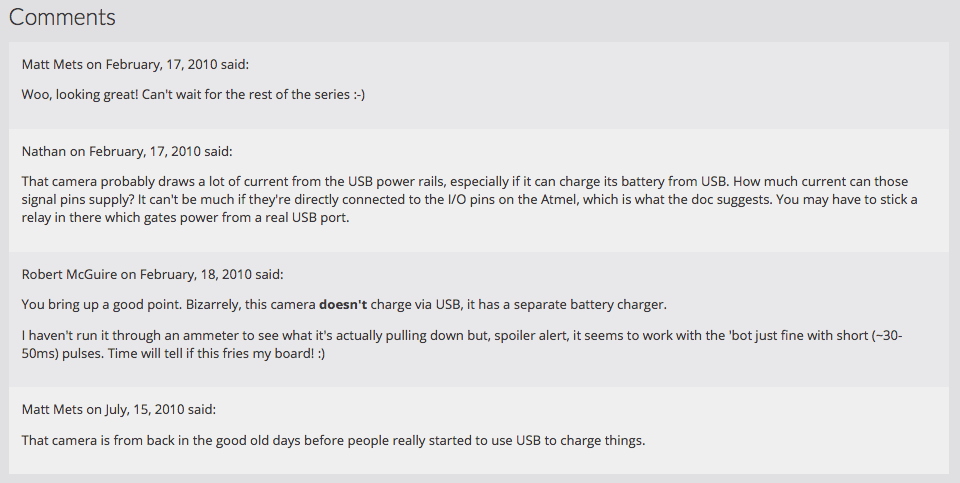
"Owning" My Disqus Comments
Though I had long ago considered them lost, I noticed that some of my old posts had a section that the Octopress importer had added to the metadata of my posts from Wordpress:
All of my Wordpress posts had this dsq_thread_id value, and that got me thinking. Could I export the old Disqus comment data and find a way to display it on my site? (Spoiler alert: yes I could).
You can request a compressed XML file containing all of your comment data, organized hierarchically into "category" (which I think can be configured per-site), "thread" (individual pages), and "post" (the actual comments), and includes info such as author name and email, the date it was created, the comment message with some whitelisted HTML for formatting and links, whether the comment was identified as spam or has been deleted, etc.
The XML format was making me queasy, and Jekyll data files often come in YAML format for editability, so I did the laziest XML to YAML transform possible, thanks to some Ruby and this StackOverflow post.
I dropped this into my Jekyll site as _data/disqus.yml, and ... that's it! I could now access the content from my templates in site.data.disqus.
I wrote a short template snippet that, if the post has a "meta" property with a "dsq_thread_id", to look in site.data.disqus.disqus.post and collect all Disqus comments where "thread.dsq:id" was the same as the "dsq_thread_id" for the post. If there are comments there, they're displayed in a "Comments" section on the page.
So now some of my oldest posts have some of their discussion back after more than 7 years!
I was (pleasantly) surprised to be able to recover and consolidate this older content. Thanks to past me for keeping good backups, and to Disqus for still being around and offering a comprehensive export.
As a bonus, since all of the comments include the commenter's email address, I could give them avatars with Gravatar, and (though they have no URL to link to) they would almost look right at home alongside the more modern mentions I display on my site.
“Above all, people need to have control of their data, a way to carve out private and semi-private spaces, and a functional public arena for politics and civil discourse. They also need robust protection from manipulation by algorithms, well-intentioned or not.”
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
brianey.com – Been working on some content based on personal notes, which he takes all the time, about things like stuff he's read, etc. Thought about turning ~5 of his notes at a time into monthly lists, but has been writing a lot. Might be more like each note becomes a paragraph-long post. He also manages a newsletter that usually covers one topic, but might automate these new "listy" posts into a collection for the newsletter.
jonathanprozzi.net – Been working on a longer content post, part two of a series that started in March about creativity and code and his personal learning journey. Wants to keep up with post-a-week challenge. Started capturing ideas because he tends to forget topics if he doesn't get started on them. Doesn't want to have long spans of time between posts, so needs a system to keep track of posting as he gets too busy to take big chunks of time.
martymcgui.re – Been working on cleaning up cruft in his site implementation, not a lot of publicly visible stuff. Also been thinking a lot about things that stop him from posting, like not being able to easily syndicate posts while on mobile, and thinking of plans to make it easier. Tonight worked on the first part of supporting micropub edits for his site by working on source queries.
We also had a good discussion about how folks track their projects, keep ongoing notes, nudge themselves to make progress, and more. We talked about tools like Google Calendar and Tasks, laverna.cc, "GTD", and more that I forgot to write down.
Left-to-right: jonathanprozzi.net, mysterious air plant, brianey.com, martymcgui.re
We hope that you'll join us for the next HWC Baltimore on May 10th back here at the Digital Harbor Foundation Tech Center! It's an "Off-Week" for the usual HWC schedule. After that we're back on track with another "On-Week" HWC on May 31st!
Update: thanks to Ryan Barrett for pointing me to his Keep Bridgy Publish dumb post, which explains why Bridgy doesn't include the features mentioned below!
Nerd alert: This post is me geeking out and will involve talk of protocols.
In keeping with the IndieWeb concept of POSSE (Publishing on my Own Site, Syndicating Elsewhere), I try to make social media posts on my own site first and then make similar (not always identical!) posts to my accounts on silos like Twitter and Facebook. I then add links to the posts on my site indicating that you can find the "syndicated copies" of that post on those silos.
My process for doing this is something like:
Make a new post, likely with a micropub client like Quill.
Log in to Twitter and make a similar post, making note of the URL to the new tweet.
Log in to Facebook and make a similar post, making note of the URL to the new FB post.
Edit the metadata to my post to indicate the new syndication links.
Re-publish the post on my site.
Because of the way my site is set up, this manual process requires the use of my laptop, so I can't do it on the go.
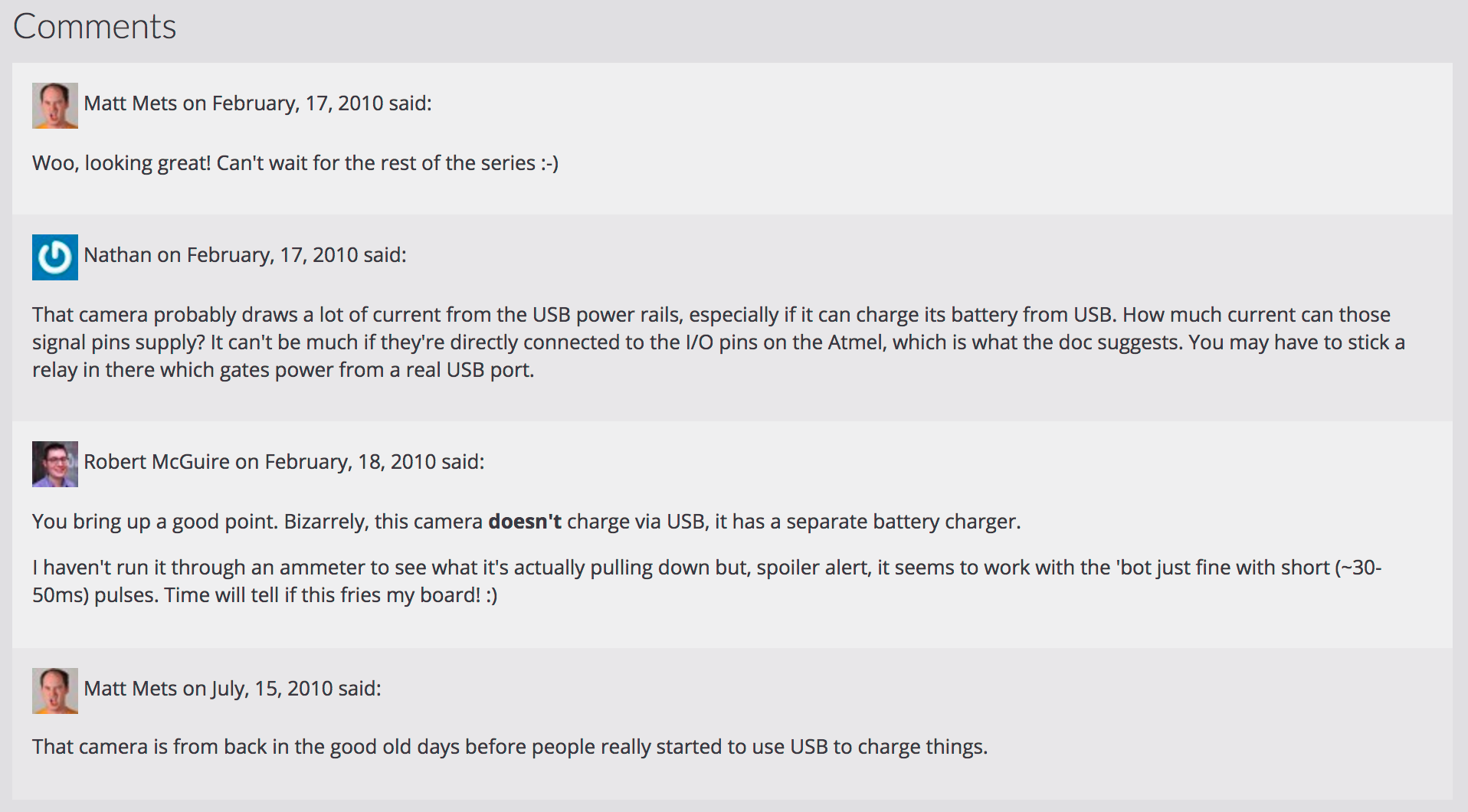
When thinking of ways to automate this process, I found myself drawn to another nice IndieWeb tool called Telegraph. Telegraph takes the URL for a post, finds links inside that post, and (if they support webmentions) allows me to notify those sites about that my post links to theirs with a single click.
Excerpt from Telegraph's UI with buttons to Send Webmention to supported URLs
I like the way Telegraph works for several reasons:
It's not purpose-built for a single website - it can be used for sending webmentions from any site that publishes their content with the right markup to any site that can receive them.
It puts the final decision to send a mention in my hands - I can choose to send mentions to any particular link mentioned in my post, or not.
With a bookmarklet, the process of sending webmentions becomes very simple. I visit the page for my post, click my Telegraph bookmark in my browser, and Telegraph shows me the links and send buttons for my post.
There already exists a great tool for copying content from my site to certain silos: brid.gy. While brid.gy's primary use case is to use webmentions to syndicate comments and other activity from silos onto your own site, brid.gy also has a Publish feature which accepts a URL from your site and attempts to create a similar post on the silo of your choice. Brid.gy Publish is a great feature, and I make good use of it. However, there are still a few pain points that I feel when using it:
While Brid.gy Publish gives a nice preview of what it will do, I can't tweak the content before publishing without editing my own post.
Brid.gy does not, as far as I can tell, support bookmarklet functionality. So, publishing takes multiple steps:
Visit my brid.gy profile page for a particular silo account.
Finally, while Brid.gy lets me know in its UI that my post succeeded, Brid.gy has no mechanism for informing my site that the new syndicated post is available. I still need to enter the syndication URLs into my post manually and re-publish my post.
With that groundwork of existing tools, here is what (I think) my ideal workflow would look like:
Make a new post to my site, likely with a micropub client like Quill.
While looking at my post, click a bookmarklet that takes me to a syndication tool.
The syndication tool shows me previews of what my post would look like on each silo where I'd like to publish. I can tweak the content, if needed.
A single "Publish" click for each silo would create the post on that silo, but would also update my website with the new syndication link.
This tool seems non-trivial to implement, but I think there are several building blocks which could be quite useful:
silo.pub is a micropub-to-multiple-silos service that can simplify the process of getting content into silos. Brid.gy Publish also does much of this.
Micropub supports updates. this could be used to add the syndication targets back to the original post. In fact, this use case is in the spec.
I am not currently aware of anyone who does POSSE with this particular flow. I would be interested to know other folks' thoughts on this! Feel free to let me know with a post on your own site that mentions this one, or hit me up in the #indieweb-dev IRC chat!
Tonight! 6:30-8:30pm at Digital Harbor Foundation Tech Center, join us for Homebrew Website Club Baltimore. Work on your website and share knowledge with folks who are doing the same!
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
Jonathan Prozzi and I have challenged one another to make a post about improving our websites once a week. I'm late with this one!
Most of the features on my website are experiments in learning new things. Sometimes I learn a better way of doing something that I've already built into the site and it's time to migrate!
Moving Media files from Git LFS to a Media Endpoint
I build my site with Jekyll, and I store my site's configuration and text content via Git. One of the things that most folks avoid with Git is storing text content (which fits into Git's model of efficiently storing differences over time) with large binary files like images, etc. (which Git cannot manage as efficiently).
When I first set up my site, I made use of Git LFS ("Large File Storage") for managing anything that wasn't text. Any images, video, or audio that I added to my site was stored in an _assets/ folder in a way that matched uploaded files to the posts they were a part of. Git LFS would transparently ship those files off to a secondary server rather than include their content in the Git repository itself. I had to go through some hoops to set up my local GitLab server to support Git LFS and to set up Git LFS with the server that handles receiving new posts via Micropub, compiling and deploying the site.
It turns out that there are many reasons that a site would want to handle media files separately from the text content that refers to them. In fact, it is a common enough pattern that the Micropub standard includes a definition for a separate "media endpoint" to handle file uploads. I shared a Micropub media endpoint implementation that I built called Spano a while back, and it has been working well with support from tools like Quill. So the text content of my site is served from https://martymcgui.re/, and my media files from https://media.martymcgui.re/. With a couple of changes in my code and my workflows, this has become the way I handle all media files for my site.
However, I still had a bunch of files in site being handled by Git LFS, and some of my Jekyll code (plugins and templates) for showing embeds expected files to be on the local filesystem. This past week I took some time to write some scripts to find all references to those local files, migrate them to my media server, and update the outgoing links. I also updated my embed handling so it didn't rely on local files. This let me delete a lot of local metadata I was keeping but not using, like all the EXIF tags in uploaded photos. I am now Git LFS free and it feels like one less thing to worry about.
Better Caching for Mentions from Webmention.io
When I finally started displaying webmentions, I had a very simple model for how to cache all the info from webmention.io. Basically: I stored all mentions in a big array and, when my site went to fetch new mentions, it would keep fetching until it saw the "last" mention again. This led to a bit of a bug where someone might send me a mention, update their page, and send the mention again. My site would not be able to recognize the "last" mention, so it would fetch all my mentions again, leading to everything appearing twice.
This past week I rewrote my mention handling to avoid this problem by replacing this array and storing mentions in a hash based on the source and target. The new code also checks to see if the verification date of the mention has changed (giving me a way to detect and notify about changed mentions in the future). I also reorganized my mention cache to include an index by the target URL on my site. This makes it a bit quicker to find mentions for a given page when rendering out the site.
Neither of these changes are really visible to readers of my site, but they have been useful for cleaning things up. The webmention.io handling in particular has brought my plugin a lot closer to being something I could release for other people to use!
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
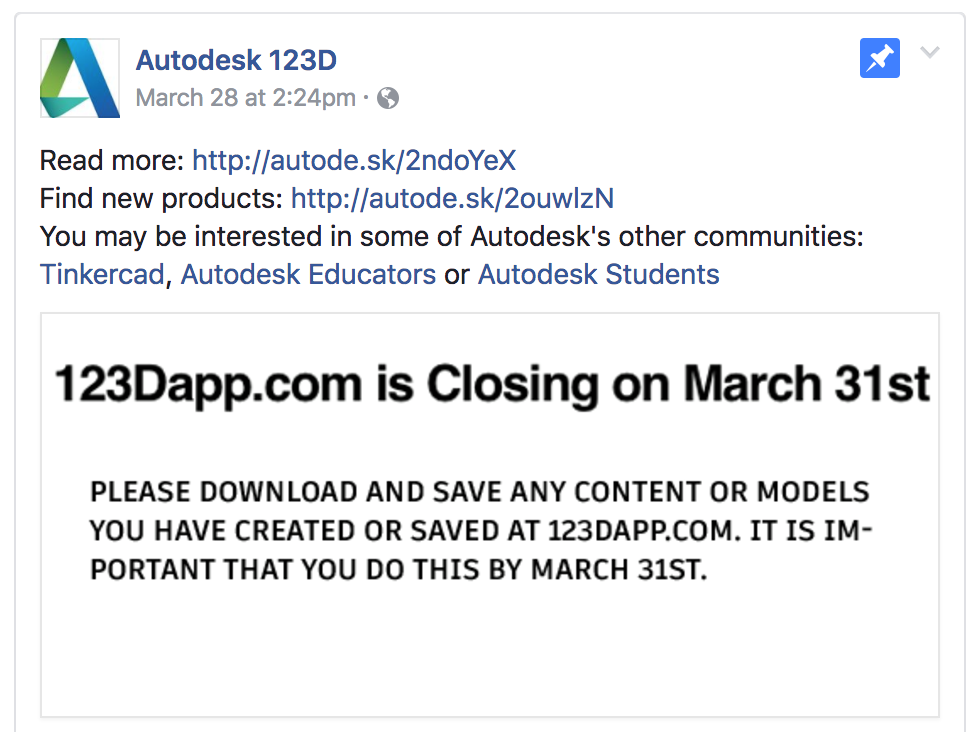
Post from Autodesk 123D Facebook page warning that 123dapp.com is closing March 31st, 2017
In their shutdown announcement, Autodesk promised that they were "consolidating these tools and features into key apps such as Tinkercad, Fusion 360, and ReMake." However, the future is anything but clear for users of the 123D apps suite.
What Were the 123D Tools?
Autodesk's many tools in the "123D" line were available at 123dapp.com, and included:
123D Design, a desktop and iOS (iPad-only) app that allowed direct manipulation of 2D and 3D shapes with a focus on creating parts with precise measurements.
123D Sculpt+, a desktop app that allowed direct manipulation of 3D shapes as though modeling with clay.
123D Catch, an iOS app that allowed users to create 3D models by taking several photos (dozens or more) and uploading them to a cloud service which analyzed them to produce a rough 3D model
123D Make, a desktop app that enabled users to "slice" existing 3D models into flat 2D designs for manufacturing on CNC machines or laser cutters. Once made, the slices can be stacked to arrive back at an approximation of the original 3D design.
However, these apps were not the entirety of the ecosystem. 123dapps.com was also a social site with sharing and collaboration features. Users could store their designs on the 123D "cloud", encourage others to remix them, import others' designs into their tools for remixing, etc.
However, one important feature was also available in almost all of these tools: the 123D tools allowed users to save and load files from their local computer and share them on any platform they liked, or not share them at all.
What are the New Tools?
Autodesk is encouraging 123D users to migrate to a handful of new tools:
Tinkercad - A manipulation modeler similar to, but missing some features of 123D Design. Rather than being a desktop app, it runs in modern web browsers. Tinkercad is widely used in education.
Fusion 360 - A desktop modeling app that is similar to 123D Design, but which offers much more powerful operations, allowing for more complex designs.
ReMake - A desktop app for Windows which can create and clean up 3D models from photos. It's similar to 123D Catch, but also works with many hardware 3D scanners.
Indeed, on the surface these seem to cover all the use cases of the 123Dapp.com tools, and in most cases provide superior features. However, there are some wrinkles.
Tinkercad is indeed free to use, but it requires users to create a cloud account and to store and share their model via the Tinkercad service. If the Tinkercad servers are down, users cannot access their files or perform any modeling. Oh, and before it was purchased by Autodesk, Tinkercad was almost shutdown entirely.
Fusion 360 offers multiple versions, a free trial and a pay edition which is free for users who can prove that they are students. However, even if one pays for the full version, Fusion 360 has one amazing anti-feature: it does not support working with local files. This means that even if a user is a paying customer, they must have fast internet access, a valid Autodesk cloud account, and abide by Autodesk's terms of service for any designs they wish to store or share.
Autodesk's shutdown of the 123D apps suite serves as an object lesson in the dangers of trusting "the cloud", but the lessons go beyond that.
The comments section of the shutdown announcement is filled with examples of educators of all stripes who are losing access to education tools. Where it is possible to migrate to the new offerings, curricula must still be rewritten. Given the nature of many school IT systems and student privacy requirements, I am willing to bet that many schools will not be able to replace 123D Design with Fusion 360 or Tinkercad at all.
The shutdown extends beyond the cloud to downloadable apps like 123D Design, as well. While Autodesk will not explicitly cripple any of the 123D tools that don't rely on cloud infrastructure, they will not offer future support or patches, and downloading them will soon become impossible. As of this writing, the Windows version of 123D Design can still be downloaded from their site. However, MacOS and iOS versions have already been pulled from Apple's app stores. Unless Autodesk commits to maintaining support for 123D Design's files in their future offerings, users will become entirely unable to work with them.
Autodesk provides powerful design tools that can be used by anyone from students with no budget up through professional engineering firms working on multi-million dollar projects. However, all Autodesk users should carefully examine the reasons for and the knock-on effects from this "consolidation". The shutdown of Autodesk 123D should make it clear that Autodesk is herding its users into a silo which will tie the fate of user's designs to the fate of Autodesk's ability and desire to run their cloud platform.
Autodesk has shown their willingness to alter the deal they make with their users. Pray they do not alter it further.
TL;DR, my site now pulls attempts to recognize single-emoji comments and display them as a "Reaction".
Slightly longer version - my site uses webmention.io for handling webmentions, and I use brid.gy to backfeed interactions from Facebook to my own site. The way brid.gy handles Facebook reactions other than the standard "like" is a little quirky - they show up in webmention.io as a "reply" with a single emoji as the "content".
Using the Ruby twemoji library, my site checks the "content" of a reply against the emoji index and, if the content is a single emoji, pulls it out of the usual "reply" display and puts it in a facepile. The emoji itself is shown as an icon in the corner of the little face image.
Example of some ❤️ reactions from Facebook
While I was at it, I cleaned up a lot of my webmention-handling template to make things much clearer. This will make things easier for folks that want to re-use this code when I (eventually) release this as a Jekyll plugin.
Tonight is a Homebrew Website Club night, but Baltimore is not having another official meetup until April 19th. Still, I wanted to get something done to continue my deal with Jonathan to post something IndieWeb related at least once per week.