I'm back again with a blog post that is almost entirely just for me to remember a thing that I did!
itch.io is a site full of great games (video and otherwise!), assets to make games, and digital art of all kinds.
Over the last few years I have been especially drawn in by the bundles, particularly the charity fundraising variety. For these bundles, dozens (sometimes more than a hundred?) creators will offer up their content so that all proceeds from buying the bundle goes towards a worthy cause.
For example, the recent Türkiye & Syria Earthquake Relief Mega Bundle had 203 items from 135 creators, with a minimum contribution of $10. That's ridiculously affordable even after bumping it up by my mental multipliers for charitable giving.
Between fundraisers and sales bundles I now have quite a few of these amounting to hundreds (thousands?) of items. It turns out that I find sifting through all this stuff to be surprisingly difficult in the itch.io interface. Until you actually download an item from a bundle, it doesn't appear in your overall library. You can browse each bundle page by page, 30 items at a time, or search within a bundle if you know exactly what you're looking for.
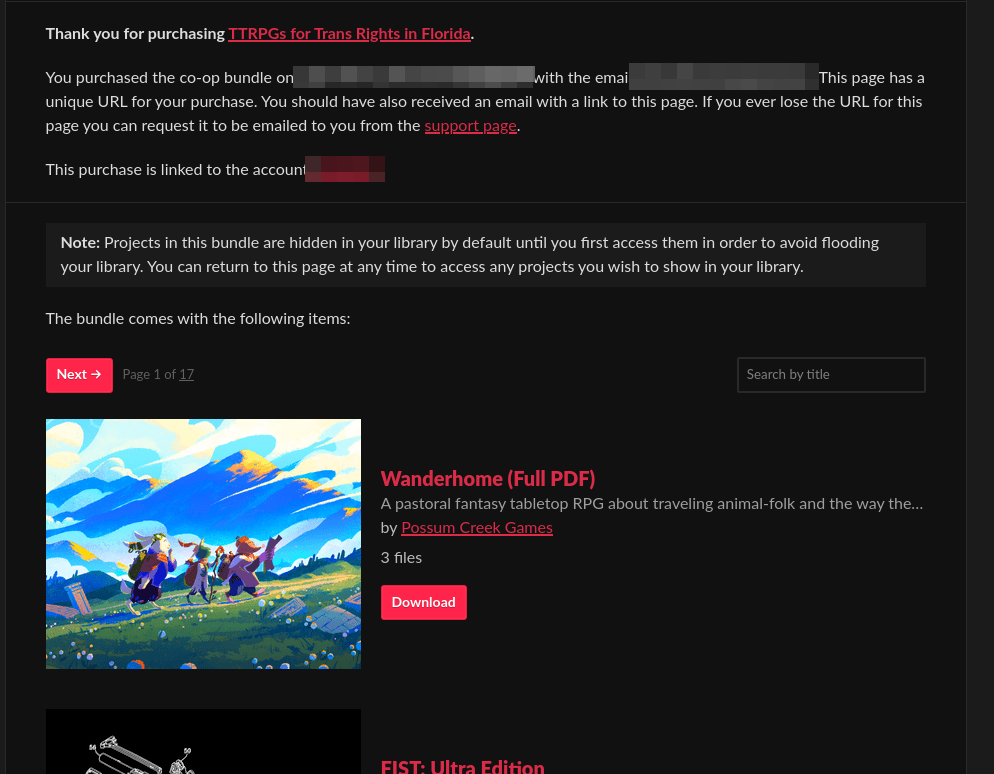
Screenshot of the TTRPGs for Trans Rights in Florida bundle first page of 17. It shows info about the bundle and the top two items, Wanderhome and FIST: Ultra Edition
However, I don't know what I'm looking for, and browsing this way feels pretty bad to me.
The part where I talk about a thing I did
Thanks to lots of help from my bookmarklets toolset and Firefox dev tools, I put together a bookmarklet that will extract the metadata (name, author, image and item page urls, ...) from all items on a given itch.io bundle download page and copy it to the clipboard as a partial JSON array.
For each bundle I opened a new .json file in my editor and proceeded to page through the bundle, using the bookmarklet to copy the data for the visible page, then paste it into the JSON file, and repeat until done. This part was not very much fun, but it wasn't too time consuming.
Now I have a couple of dozen .json files describing the contents of all the bundles I've purchased on itch.io. Hooray!
As a quick does-this-work test, I added them to my personal notes site, which is powered by Hugo. I dropped the .json files into a data/itch/bundles/ folder, then made a corresponding Markdown file in content/itch/bundles/ to match. I added a new layouts/itch/single.html file that pulls the info from .Site.Data.itch.bundles and displays it.
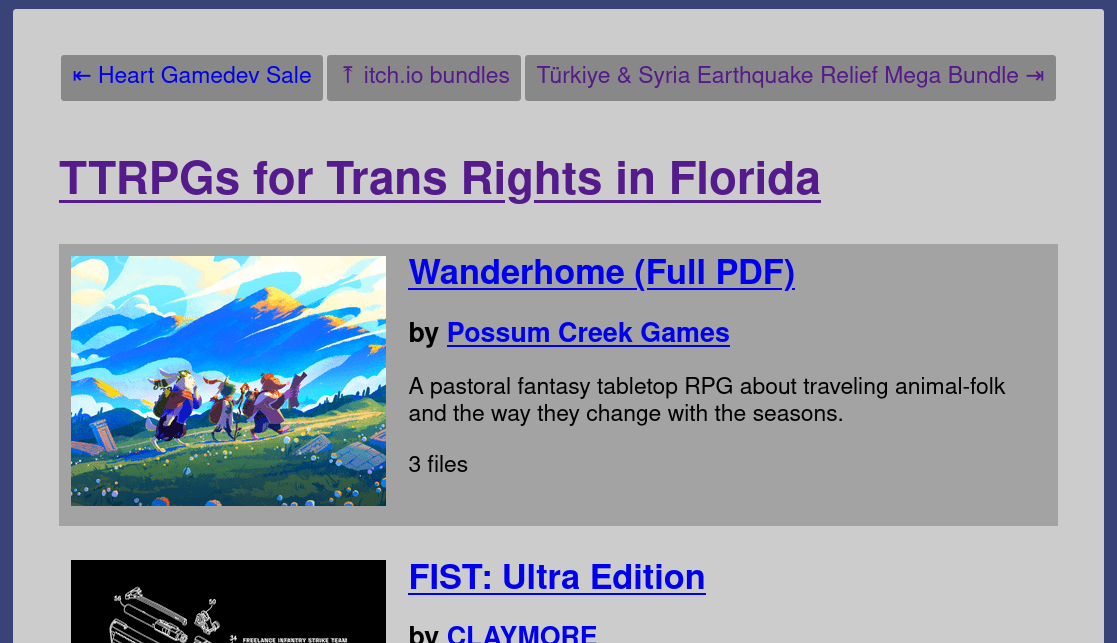
Screenshot of the TTRPGs for Trans Rights in Florida bundle in my notes site. Top entries are shown for Wanderhome and FIST: Ultra Edition
The part where I talk about next steps
Now I can scroll through an entire bundle's content on one page, rather than paging through 30 at a time! This is... not actually that useful. However, the main win here is that with a pile of .json files I can start to do more interesting things like organizing all these items across bundles. De-duplicating, sorting, tagging, and more.
This is also me opening the door to other personal itch.io meta projects. For example, they have a "collections" system that I'd love to have syndicated into my personal bookmarks. Each project/game/whatever on itch.io also has a blog available, and itch.io lets you Like these posts. It'd be nice to have those syndicate to my website, too!
“I’m going to be talking about personal data warehouses, what they are, why you want one, how to build them and some of the interesting things you can do once you’ve set one up.”
First, some backstory. But feel free to skip to the good stuff!
With topics ranging from media and social critiques, to making and tech topics that I care about, to death itself, regular content from creators that post on YouTube have been a part of my daily life for the last several years.
This is enabled by three main features:
Subscriptions, to let me check in for new videos from creators I want to follow.
The Watch Later playlist, to let me save videos I wanted to include in my regular watching.
A YouTube app connected to my TV to let me play through my Watch Later list.
Over time, I feel that YouTube has been consistently chipping away at this experience for the sake of engagement.
In 2016, when I found the advertisements to be too invasive, I became a paid "YouTube Red" (now YouTube Premium) subscriber. With ads gone, and with so many content creators posting weekly or more, it was easy to let watching videos through YouTube become a regular habit. Turning off and clearing my YouTube viewing history helped mitigate some of the most creepy aspects of the suggestion system, at the cost of being able to track what I'd seen.
This replaced a lot of idle TV watching time. For several years!
"Progress" marches on, however, and the next thing to go was the experience of accessing the Watch Later playlist. I first noticed this after updating to a 4th generation Apple TV. From the (suggestion-cluttered) main screen of the YouTube app, you must make a series of precise swipes and taps down a narrow side menu to "Library", then to "Watch Later", then to the video that you'd like to start. Not long after, I noticed that the YouTube iOS app and the website itself had similarly moved Watch Later behind a "Library" option that was given the smallest of screen real-estate, overwhelmed by various lists of suggestions of "Recommended for You", "Channels You Might Like", and more.
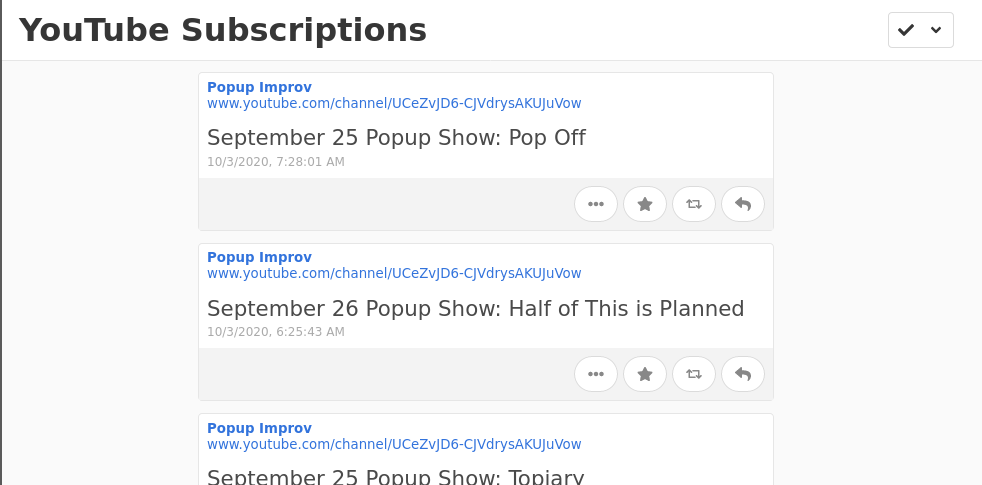
Most recently, I noticed that YouTube has been changing the definition of a "subscription", where the iOS app will show a timeline of text posts and ephemeral "Moments" in between the actual video content that I am trying to see. Or they'll (experimentally?) try to chunk the subscription display by days or weeks.
All the while, this extra emphasis on recommended videos wore me down. I found myself clicking through to watch stuff that I had not planned to watch when sitting down. Sometimes this would be a fun waste of time. Sometimes I'd get dragged into sensationalized news doom-and-gloom. Regardless, I felt I was being manipulated into giving my time to these suggestions.
And hey, it's #Blocktober, so let's see if we can escape the algorithm a bit more.
A Plan
What I would like to achieve is what I described at the top of my post:
I want a way to check for new videos from creators I follow (no notifications, please).
I want a way to add those to a list for later viewing.
I want to view items from that list on my TV.
I have some tools that can help with each part of that plan.
RSS is (still) not dead
Feeds are already part of my daily life, thanks to an indie social reader setup. I run Aperture, a Microsub server that manages organizing source feeds in various formats, checking them periodically for new content, and processing them into items grouped by channel. I can browse and interact with those items and channels via Microsub clients, like Monocle which runs in the browser and on my mobile devices with an app called Indigenous.
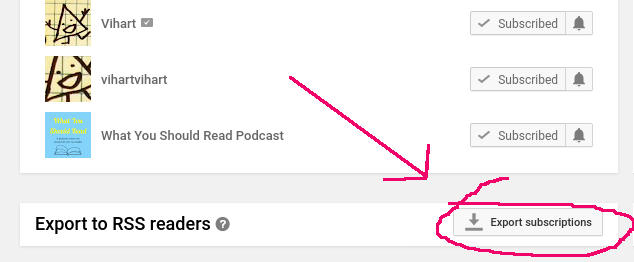
Did you know that YouTube provides an RSS feed for every channel? It's true! In fact, if you visit your Subscription manager page, you'll find a link that the bottom to download a file containing the feed URLs for all of your subscriptions in a format called OPML.
Screenshot a an interface listing channel subscriptions. At the bottom is an entry named "Export to RSS readers" with a button labeled "Export subscriptions". The button is highlighted with hand-drawn pink annotations of an arrow and a circle.
My YouTube subscriptions download had more than 80 feeds (yikes!) so I didn't want to load these into Aperture by hand. Thankfully, there's a command-line tool called ek that could import all of them for me. I had a small issue between ek's expectations and YouTube's subscription file format, but was able to work around it pretty easily. Update 2020-10-04: the issue has already been fixed!
A list of feed URLs in ApertureA list of videos in Monocle, showing channel name and video title.
With Aperture taking care of checking these feeds, I can now look at a somewhat minimal listing of new videos from my subscribed channels whenever I want. For any new video I can see the channel it came from, the title of the video, and when it was posted. Importantly, I can click on it to open the video in the YouTube app to watch it right away or save it for later.
This feels like a lot of work to avoid the mildly-annoying experience of opening the YouTube app and browsing the subscriptions page.
We must go further.
Save me (for later)
In addition to fetching and parsing feeds, Aperture also has a bit of a secret feature: each channel has an API, and you can generate a secret token which lets you push content into that channel, via an open protocol called Micropub.
So in theory, I could browse through the list of new videos in my YouTube Subscriptions channel, and — somehow — use Micropub to save one of these posts in a different channel, maybe named Watch Later.
This is where we introduce a super handy service called Indiepaper. It's a bit of web plumbing which essentially takes in a URL, gets all the nice metadata it can figure out (what's the title of this page? who's the author? etc.), and creates a Micropub post about it, wherever you want.
The real ✨magic✨ of Indiepaper comes in the form of utilities that making adding an item as few clicks as possible.
For your desktop web browser, Indiepaper can take your channel's Micropub URL and key and generate a bookmarklet which will send the current page you're looking at straight to your Watch Later channel. Add it to your browser's bookmark toolbar, load a YouTube video, click "Watch Later", and you're done!
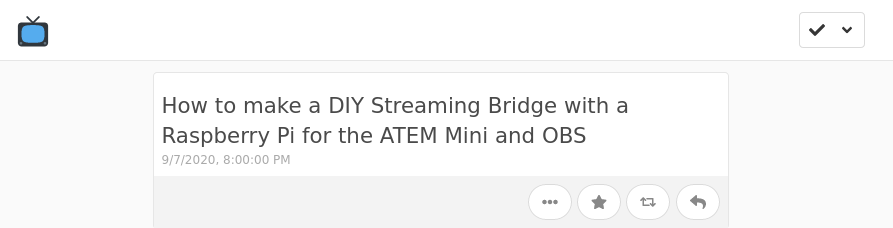
For an iOS device, Indiepaper also provides a Shortcut that works the same way. Share a YouTube video URL (from the YouTube app, or straight from your reader) to the Shortcut and it adds the item to the channel right away.
Screenshot of a Watch Later channel in Monocle with the saved video.
At this point I can:
Browse new videos from my subscriptions in my feed reader.
Save videos on demand to a separate watch later channel in my feed reader
However, something is missing. I still want to be able to watch these, distraction-free, on my TV.
The Last (and Longest) Mile
This is where things get ugly, folks. It is also where I admit that this project is not finished.
As far as I'm aware there are no apps for any "smart" TV or media appliance that can browse a Microsub channel. Much less one that can identify a video URL and send it off to the appropriate app for playback.
However, there are some existing ways to save media on your home network and play it back on your TV, such as Plex or Kodi.
So, here are some highlights:
Assuming you've got a Plex server with a library called "myTube". Your TV (maybe through an appliance) can run a Plex app that lets you browse and play that local media distraction-free.
An automated task on that server could act as a Microsub client, periodically looking in your Watch Later channel for new entries.
For each new entry, the automated task could fetch the video with a tool like youtube-dl and save it to the myTube folder, where Plex will find it.
Little details:
To prevent repeated downloads, the automated task should either delete or mark new entries as "read" once they've been downloaded.
Plex doesn't have an easy way to delete media from the TV interface. Perhaps the automated task can check with Plex to see if a video has been watched and, if so, remove it from myTube. Or maybe save it to a "watched" list somewhere!
If this feels like a lot of work just to avoid some engagement temptation, that's because it is! It may sound simple to say that someone should build a competitor to YouTube that focuses on creators and viewers. One that doesn't seem to spend all its time pushing ads and pulling on you for engagement and all the other things that go into funding a corporate surveillance-driven behemoth.
But no matter how easy it feels to browse a slickly animated user interface that pushes carefully coached eye-grabbing thumbnails of videos with carefully coached compelling titles, there is a lot about video - even watching video - that is not easy!
It's good to stay mindful of what these services make easy for you, what they make hard, and what they make impossible. Trying to take charge of your own consumption is barely a first step.
What aspects of social media are you shutting down for yourself in #Blocktober?
It looks like I will be speaking at IndieWeb Summit! Specifically, I’ll be giving a keynote about how to “Own Your Mobile Experience”.
As a long-time enthusiast for these tiny computers we carry, I try to make most of the things I can do online into things I can do on my phone or tablet. That turns out to be… a lot of things.
I’ll probably keep the technical details light, other than naming specific IndieWeb building blocks that each piece relies on. I plan to make a (set of?) posts on my site explaining the plumbing, afterwards.
With just about a week and a half left to plan my ~10-15 minute set of demos, here are some things I am thinking of discussing / demoing.
Reading! With an [indie reader](https://indie web.org/reader) setup based on Microsub and the Indigenous iOS app.
Including following folks on Instagram and Twitter with the help of Granary
Replying and responding to things I read directly on my site via Indigenous and Micropub.
Posting my own notes and photos with Indigenous and Micropub
Seeing notifications on my devices when someone posts a response to my own posts.
I'm in the middle of a Forever Project, migrating stuff and services off of an old server in my closet at home onto a new (smaller, better, faster!) server in my closet at home.
One such service is a Matrix.orgSynapse homeserver that was used as a private Slack-alternative chat for my household, as well as a bridge to some IRC channels. I set it up by hand in haste some years ago and made some not-super-sustainable choices about it, including leaving the database in SQLite (2.2GB and feelin' fine), not documenting my DNS and port-forwarding setup very well, and a few other "oopsies".
I found some docs on the most recent ways to set up Matrix on a new server, and even on how to migrate from SQLite to PostgreSQL. However, I don't know if I'll be able to set aside the time to do it all at once, or if it'll be easier just to set it up fresh, or even if I need a homeserver right now. So, I decided to figure out how to make archives of the rooms I cared about, which included household conversations, recipes, and photos from around the house and on travels.
Overview
The process turned out to be pretty involved, which is why it gets a blog post! It boils down to needing these three things:
matrix-org/pantalaimon - A proxy to handle end-to-end encrypted (E2EE) room content for matrix-archive
matrix-org/Olm - C library to handle the actual E2EE processing. Pantalaimon relies on this library and it's Python extensions.
Getting all the tools built required a pretty recent system, which my old server ain't. I ended up building and running them on my personal laptop, running Ubuntu 19.04.
Since both matrix-archive and pantalaimon are Python-based, I created a Python 3.7 virtualenv to keep everything in, rather than installing everything system-wide.
Olm
The Olm docs recommend building with CMake, but as someone unfamiliar with CMake I could get it to build and run tests, but could not actually get it installed on my system.
I ended up installing the main lib with:
make && sudo make install
The Python extensions were a challenge and I am not sure that I remember all the details to properly document them here. I spent a good amount of time trying to follow the Olm instructions to get them installed into my Python virtualenv.
In the end, the pantalaimon install built its own version of the Python Olm extensions, so I'm going to guess this was enough for now.
Pantalaimon
The pantalaimon README was pretty straightforward, once I installed Olm system-wide. I activated my virtualenv and ran:
python setup.py install
That resulted in a "pantalaimon" script installed in my virtualenv's bin dir, so I could (in theory) run it on the command line, pointing it at my running Synapse server:
pantalaimon https://matrix.example.com:8448
That started a service on http://127.0.0.1:8009/ which matrix-archive would connect over, with pantalaimon handling all the E2EE decryption transparently.
matrix-archive
The matrix-archive setup instructions suggest using a dependency manager called "Pipenv" that I was not familiar with. I installed it in my virtualenv, then ran it to setup and install matrix-archive:
pip install pipenv
pipenv install
Pipenv "noticed" it was running in a virtualenv, and said so. This didn't seem to be much of a problem, but any command I tried to run with "pipenv run" would fail. I worked around this by looking in the "Pipfile" to see what commands were actually being run, and it turns out it was just calling specific Python scripts in the matrix-archive directory. So, I resolved to run those by hand.
MongoDB
matrix-archive requires MongoDB. I don't use it for anything else, so I had to "sudo apt install mongodb-server".
Running the Import
First, I set the environment variables needed by matrix-archive:
At the end, it said it had a bunch of messages. Hooray!
Running the Export
This is where things kind of ran off the rails. In trying to export messages I kept seeing Python KeyErrors about a missing 'info' key. It seems like maybe the Matrix protocol was updated to make this an optional key, but the upshot was that matrix-archive seemed to assume that every message with an image attached would have an 'info' with info about a thumbnail for that image.
Additionally, the script to download images had some naive handling for turning attachment URLs like "mxc://example.com/..." into downloadable URLs. Matrix supports DNS-based delegation, so you can say "the Matrix server for example.com is matrix.example.com:8448, and this script didn't handle that.
I did some nasty hacks to only get full-sized images, and from the right host:
updated the schema to return the full image URL instead of digging in for a thumbnail
added handling to export_messages.py to handle missing 'info', which was used to guess image mimetypes
added some hardcoding to map converted "mxc://" URLs to the right host.
Afterwards I was able to do an export of alllllll the images to a "images/" folder:
python download_images.py --no-thumbnails
And could then export a particular room's history with:
Note that the "--room-id" flag above actually wants the human-readable room name, unless it's actually a room on the main matrix.org server.
Afterwards, I could open room-name.html in my browser, and see the very important messages and images I worked so hard to archive.
Screenshot from the (very minimal) HTML export, including an image (of a pug, sourced by a chat bot).
What's Next?
For now, I'll be putting these files and images in a safe backup and not worrying about them too much, because I have them. I've already stopped my old Synapse server, and can tackle setting up the new one at my leisure. We've moved our house chats to Signal, and I've moved my IRC usage over to bridged Slack channels.
Running a Matrix Synapse homeserver for the past couple of years has been quite interesting! I really appreciate the hard working community (especially in light of their recent infrastructure troubles), and I recognize that it's a ton of work to build a federating network of real-time, private communication. I enjoyed the freedom of having my own chat service to run bots, share images, and discuss private moments without worrying about who might be reading the messages now or down the road.
That said, there are still some major usability kinks to work out. The end-to-end encryption rollout across homeservers and clients hasn't been the smoothest, and it can be an issue juggling E2EE keys across devices. I look forward to seeing how the community addresses issues like these in the future!
TL;DR - saving an archive of a room's history and files should not be this hard.
Netflix has been a staple in my life for years, from the early days of mailing (and neglecting) mostly-unscratched DVDs through the first Netflix original series and films. With Netflix as my catalog, I felt free to rid myself of countless DVDs and series box sets. Through Netflix I caught up on "must-see" films and shows that I missed the first time around, discovered unexpected (and wonderfully strange) things I would never have seen otherwise. Countless conversations have hinged around something that I've seen / am binging / must add to my list.
At times, this has been a problem. It's so easy to start a show on Netflix and simply let it run. At home we frequently spend a whole evening grinding through the show du jour. Sometimes whole days and weekends disappear. This be can true for more and more streaming services but, in my house, it is most true for Netflix. We want to better use our time, and avoid the temptation to put up our stocking'd feet, settle in, and drop out.
It's easy enough to cancel a subscription, and even easier to start up again later if we change our minds. However, Netflix has one, even bigger, hook into my life: my data. Literal years of viewing history, ratings, and the list of films and shows that I (probably) want to watch some day. I wanted to take that data with me, in case we don't come back and they delete it.
Netflix had an API, but after they shut it down in 2014, it's so far dead that even the blog post announcing the API shutdown is now gone from the internet.
Despite no longer having a formal API, Netflix is really into the single-page application style of development for their website. Typically this is a batch of HTML, CSS, and JavaScript that runs in your browser and uses internal APIs to fetch data from their service. Even better, they are fans of infinite scrolling, so you can open up a page like your "My List", and it loads more data as you scroll, until you've got it all loaded in your browser.
Once you've got all that information in your browser, you can script it right out of there!
Each of these pages displays slightly different data, in HTML that can be extracted with very little javascript, and each loads more data as you scroll the page until it's all loaded. To extract it, I needed some code to walk the entries on the page, extract the info I want, store it in a list, turn the list into a JSON string, and the copy that JSON data to the clipboard. From there I can paste that JSON data into a data file to mess with later, if I want.
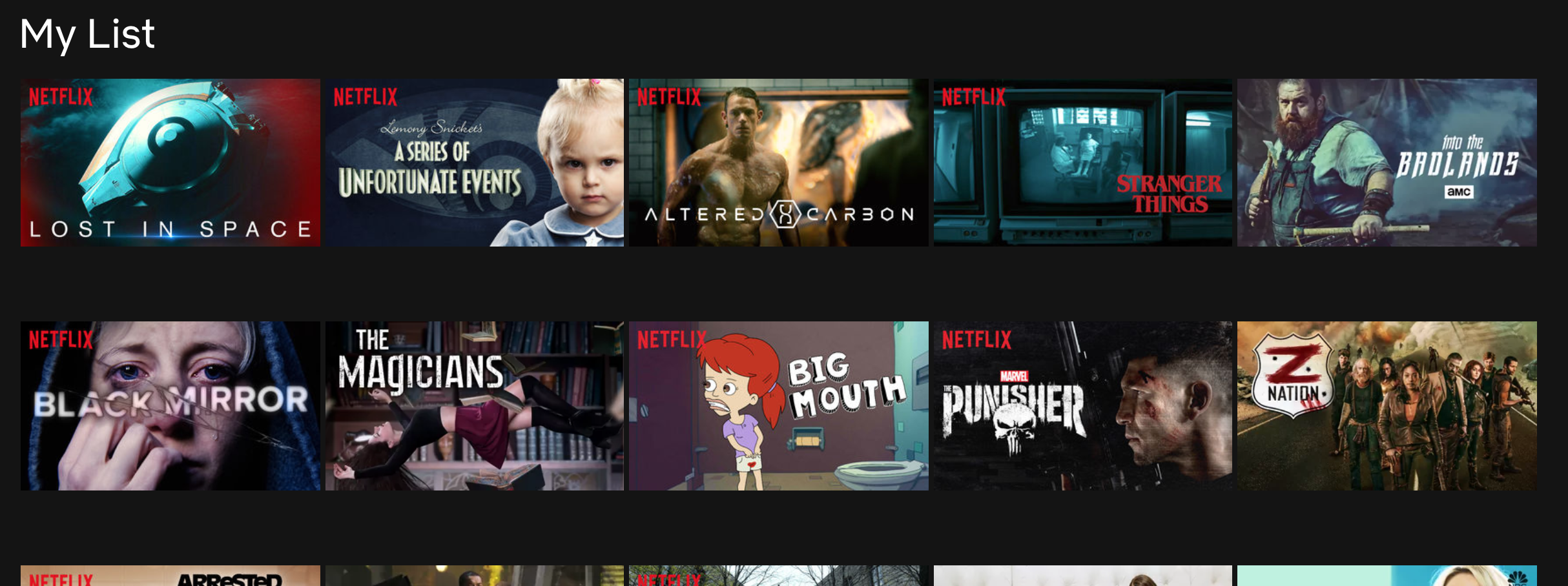
Extracting my Netflix Watch List
A screenshot of my watch list
The My List page has a handful of useful pieces of data that we can extract:
Name of the show / film
URL to that show on Netflix
A thumbnail of art for the show!
After eyeballing the HTML, I came up with this snippet of code to pull out the data and copy it to the clipboard:
I like this very much! I probably won't end up using the Netflix URLs or the art, since it belongs to Netflix and not me, but a list of show titles will make a nice TODO list, at least for the shows I want to watch that are not on Netflix.
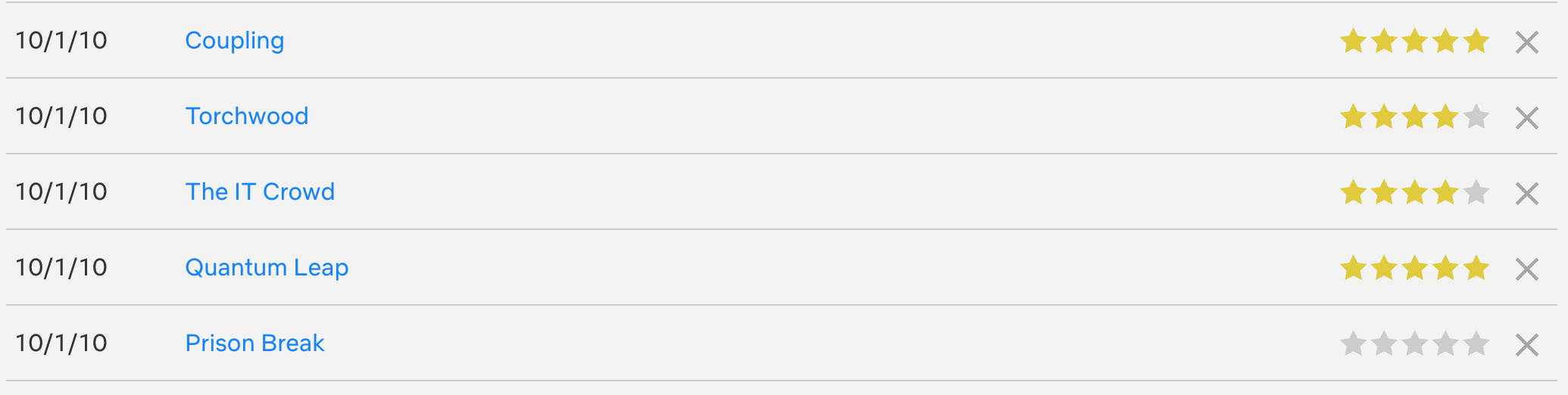
Extracting my Netflix Ratings
A screenshot of my ratings list
More important to me than my to-watch list was my literal years of rating data. This page is very different from the image-heavy watch list page, and is a little harder to find. It's under the account settings section on the website, and is a largely text-based page consisting of:
date of rating (as "day/month/year")
title
URL (on Netflix)
rating (as a number of star elements. Lit up stars indicate the rating that I gave, and these can be counted to get a numerical value of the number of stars.)
The code I used to extract this info looks like this:
While the URL probably isn't that useful, I find it super interesting to have the date that I actually rated each show!
One thing to note, although I wasn't affect by it, Netflix has replaced their 0-to-5 star rating system with a thumbs up / down system. You'd have to tweak the script a bit to extract those values.
Extracting my Netflix Watch History
A screenshot of my watch history page
One type of data I was surprised and delighted to find available was my watch history. This was another text-heavy page, with:
[
{
"date": "3/20/18",
"title": "Marvel's Jessica Jones: Season 2: \"AKA The Octopus\"",
"url": "/title/80130318"
},
...
]
Moving forward
One thing I didn't grab was my Netflix Reviews, which are visible to other Netflix users. I never used this feature, so I didn't have anything to extract. If you are leaving and want that data, I hope that it's similarly easy to extract.
With all this data in hand, I felt much safer going through the steps to deactivate my account. Netflix makes this easy enough, though they also make it extremely tempting to reactivate. Not only do they let you keep watching until the end of the current paid period – they tell you clearly that if you reactivate in 10 months, your data won't be deleted.
That particular temptation won't be a problem for me.
“Fast forward a few years: the canonical source is gone. Images, videos, texts, thoughts, life fragments deleted. Domains vanished, re-purposed, sold. There are no redirects, just a lot of 404 Not Found.”
Jonathan Prozzi and I have challenged one another to make a post about improving our websites once a week. Here's mine!
Back in 2008 I started a new blog on Wordpress. It seemed like a good idea! Maybe I would post some useful things and someone would offer me a job! I wanted to allow discussion without the dangers of letting strangers submit data directly to my server, so I set up the JavaScript-based Disqus comments service. I made a few posts per year and it eventually tapered off and I largely forgot about it.
In February 2011 I participated in the Thing-a-Day project on Posterous. It was the first time in a long time that I had published consistently, so when it was announced that Posterous was going away, I worked hard to grab my content and stored it somewhere.
Eventually it was November 2013, Wordpress was "out", static site generators were "in", and I wanted to give Octopress a try. I used Octopress' tools to import all my Wordpress content into Octopress, forgot about adding back the Disqus comments, and posted it all back online. In February 2014, I decided to resurrect my Posterous content, so I created posts for it and got everything looking nice enough.
In 2015 I learned about the IndieWeb, and decided it was time for a new approach to my identity and content online. I set up a new site at https://martymcgui.re/ based on Jekyll (hey! static sites are still "in"!) and got to work adding IndieWeb features.
Well, today I decided to get some of that old content off my other domain and into my official one. Thankfully, with Octopress being based on Jekyll, it was mostly just a matter of copying over the files in the _posts/ folder. A few tweaks to a few posts to make up for newer parsing in Jekyll, my somewhat odd URL structure, etc., and I was good to go!
"Owning" My Disqus Comments
Though I had long ago considered them lost, I noticed that some of my old posts had a section that the Octopress importer had added to the metadata of my posts from Wordpress:
All of my Wordpress posts had this dsq_thread_id value, and that got me thinking. Could I export the old Disqus comment data and find a way to display it on my site? (Spoiler alert: yes I could).
You can request a compressed XML file containing all of your comment data, organized hierarchically into "category" (which I think can be configured per-site), "thread" (individual pages), and "post" (the actual comments), and includes info such as author name and email, the date it was created, the comment message with some whitelisted HTML for formatting and links, whether the comment was identified as spam or has been deleted, etc.
The XML format was making me queasy, and Jekyll data files often come in YAML format for editability, so I did the laziest XML to YAML transform possible, thanks to some Ruby and this StackOverflow post.
I dropped this into my Jekyll site as _data/disqus.yml, and ... that's it! I could now access the content from my templates in site.data.disqus.
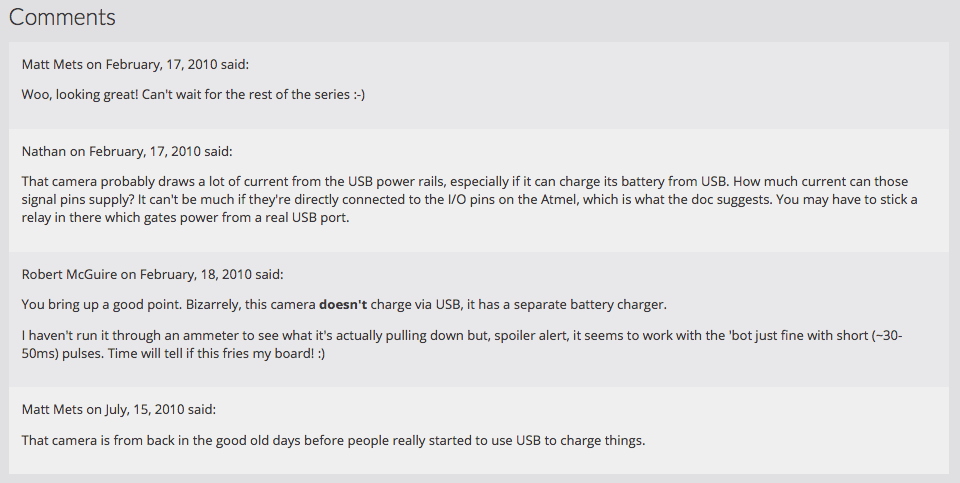
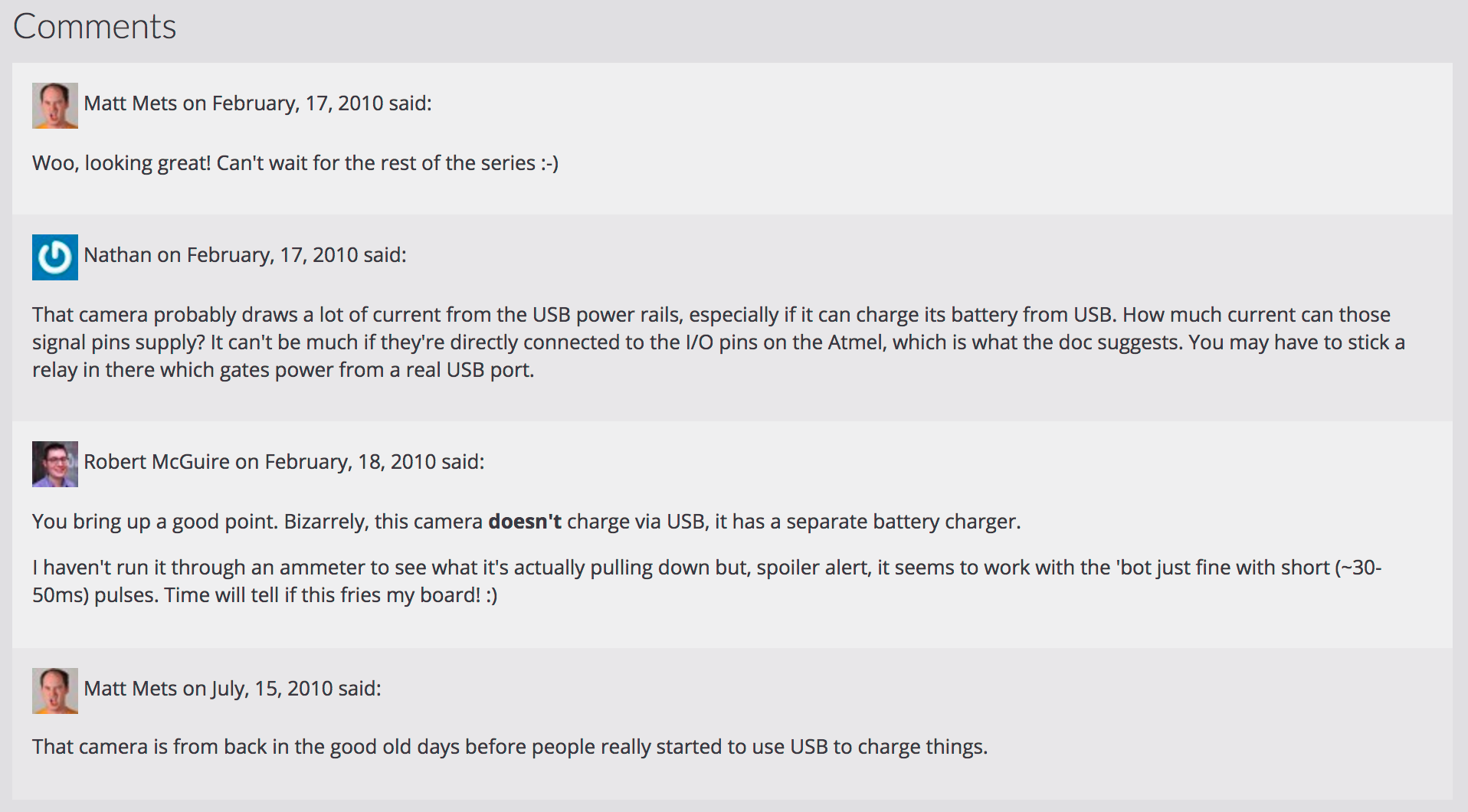
I wrote a short template snippet that, if the post has a "meta" property with a "dsq_thread_id", to look in site.data.disqus.disqus.post and collect all Disqus comments where "thread.dsq:id" was the same as the "dsq_thread_id" for the post. If there are comments there, they're displayed in a "Comments" section on the page.
So now some of my oldest posts have some of their discussion back after more than 7 years!
I was (pleasantly) surprised to be able to recover and consolidate this older content. Thanks to past me for keeping good backups, and to Disqus for still being around and offering a comprehensive export.
As a bonus, since all of the comments include the commenter's email address, I could give them avatars with Gravatar, and (though they have no URL to link to) they would almost look right at home alongside the more modern mentions I display on my site.