This map is made for you and me
Well, it's a rainy day and a good day for someday projects. Also, oops, here's a post about a tiny site update that accidentally sprawled into a post about 6 (or 14) years of my relationships with Foursquare and the whole idea of sharing "check in"s (not 🐔s).
Oh no it's backstory time
In 2009 I was living in Pittsburgh, working as a research programmer at Carnegie Mellon, a proud member of the newly formed HackPGH hacker space, starting down the slippery slope of joining the 3D printing industry, and basically excited about technology and the future. It was in this context that I vaguely remember being talked into joining Foursquare, so friends and I could keep up with one another at our usual haunts around town.
I'm not sure how much serendipity it really enabled, but checkins did lead to conversations and a nice general awareness of what folks in my social network were up to. Oh, and some competition for points and mayorships, of course, thanks to gamification.
I made use of checkins pretty regularly, in town and on trips, across a move to Baltimore and starting a new job in the aforementioned 3D printing industry. And then in 2012 I stopped. I don't 100% remember making this a conscious choice, but I do recall that most of my friends who used the app regularly were far away in Pittsburgh, privacy and surveillance capital concerns were on the rise, and — heck — I probably changed phones or something and just plain didn't install it.
Fast-forward about 5 years to 2017 and I'm all-in on the IndieWeb community. After learning about it in ~2015, putting together my first blog since ~2003, and attending my first IndieWebCamp in NYC in 2016, I found myself in Portland, OR for the IndieWeb Summit.
And goodness these folks liked checking in with Foursquare (now Swarm)! They were tagging one another in the app, maximizing points with photos, just documenting the heck out of where we were going and what we were doing.
Aaron Parecki, one of the co-founders of IndieWeb, had set up a service called OwnYourSwarm which you could set up to watch your Swarm account for new checkins, at which point it would send 'em off your your website. While I probably should have been paying more attention to the excellent IndieWeb Summit discussions, I hacked up some bits of my site to understand posts from OwnYourSwarm and posted my first checkin to my own site.
OwnYourSwarm is still around and working well, despite some speedbumps over the years from Swarm API changes. Thanks, Aaron!
Okay, but something about maps?
Speaking of Aaron, I was jealous of how good his checkin posts looked. Like this example checking in for IndieWeb Summit day 1. I specifically liked the little map at the top and wanted one for myself.
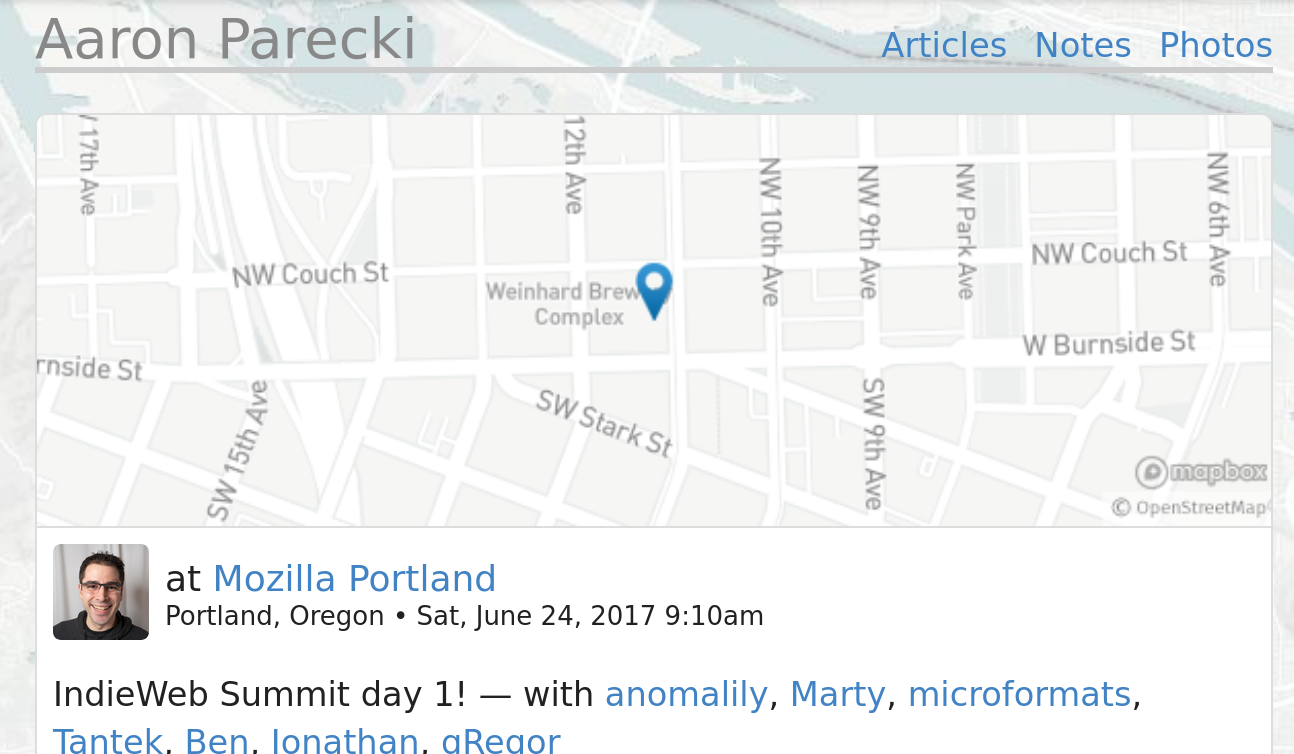
So, uh, almost a year later, I was inspired by this really great post on privacy-preserving, self-hosted maps by Sebastian Greger, to finally put together my own setup and promptly never blogged about it. I know this because I bookmarked his post and found the Git commit from June 25th, 2018 where I switch from Javascript-powered Mapbox (which I don't really recall setting up) to my own static map setup.
(Would we be shocked to discover that, on June 25th, 2018, I was checking in for that year's IndieWeb Summit? We should not be.)
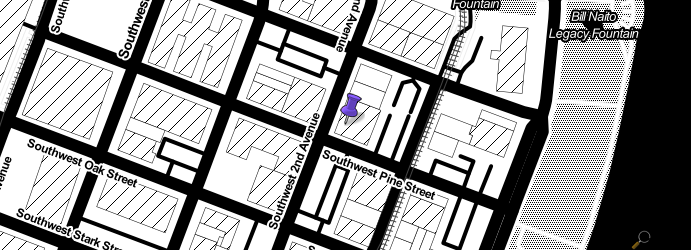
The closest thing to a write-up on my own site I was able to find was this comment I had made on a great post by Jeremy Keith about a map project of his own:
I use https://github.com/dfacts/staticmaplite on my site. It’s no longer under development but, as long as you point it at a working tilemap server, it works fine! I switched out the URLs hardcoded in the PHP file for the Stamen “Toner” tiles, using the tile server URL pattern on the Open Street Map wiki.
staticMapLite is a little PHP service you can self-host that creates plain old map images, of the locations you want at the sizes you want with overlays and pins if you want them, and caches them forever. It does so the same way as pretty much all map tools on the web: by asking bigger servers (called "tile servers", or "raster tile servers") for larger sets of "tile" images, then slicing up those tiles to make the image you want. The project is archived and hasn't seen updates since 2018, but it works fine! Raster tile server technology hasn't changed much since then.
Assuming, that is, that you have a raster tile server! You can run your own, but they require a ton of storage for all the map data, need regular updates, and generally are considered a pain to maintain.
When I set this up I remember looking over the list of raster tile servers on the Open Street Map wiki to find one that was free, didn't require signup, and produced map images that were aesthetic and minimal. With its dithered black and white look, Stamen's Toner definitely fit the bill. Stamen, those data visualization folks, right? I don't really remember thinking too hard about it!
We were promised a site update
Okay, okay! As it turns out Stamen also didn't like being maintainers of map tile servers. Especially when so many folks were freeloading on them!
To that end, this year Stamen announced a partnership with Stadia to begin hosting Stamen's many tile designs with Stadia, a map service with a business model, instead. The tile images remain shareable under their Creative Commons attribution license, I can keep all my existing cached images, and so on. They're offering a free tier of up to 200,000 tile images a month which is welllll below what I'll need for my few static images on rare times that I make checkin posts.
Stadia has their own page about the Stamen maps project, and a fairly straightforward migration guide to using Stamen map tiles served by Stadia tile servers.
So, I've updated my deployment of staticmaplite to pull tiles from Stadia. Steps largely followed their migration guide:
- Make a (free) Stadia account.
- Generate an API key.
- Update staticmap.php to replace the "a.tile.stamen.com" map URL with "https://tiles.stadiamaps.com/tiles/stamen_toner/{Z}/{X}/{Y}.png?api_key=MY_API_KEY_HERE".
-
Update my post template with the new attribution requirements.
I went hunting around the map cache on my server to find the most recent map image and delete the cached image so it would re-generate. It took me a couple of tries to get my tiles.stadiamaps.com URL correct, as Stadia's example used lowercase placeholders like "{x}" while staticmapslite requires uppercase like "{X}". Also, Stadia supports an optional "{r}" value — either an empty string "" or "@2x" if you want double-resolution images for Retina displays — that staticmaplite doesn't understand (and that I opted not to use).
Anyway, here's that most recent checkin, using the new map image.
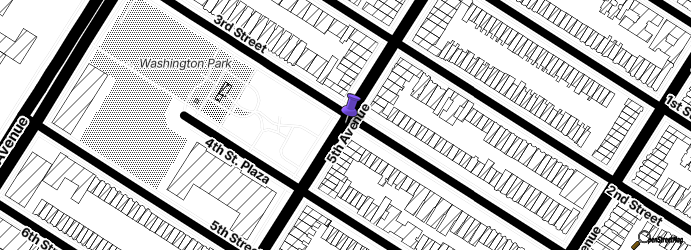
Looks pretty much the same, which is the point!
So.
Was this a site update? Perhaps one long overdue from 2017 or 2018? Or is this a post about a very specific kind of admin tax? Or something else? I'm interested in your thoughts!