Site Updates: Webmention Notifications in Matrix with Hubot
Jonathan Prozzi and I have challenged one another to make a post about improving our websites once a week. This is me getting back on the train!
In a previous site update I wrote about setting up a system to notify me whenever my site received webmentions. Essentially, this meant that I could now get notifications on my phone and desktop whenever somebody interacted with my site, such as: replying to one of my posts on their own site, retweeting or favoriting one of my posts, or even RSVPs to my Facebook events.
One thing I didn't super like about this system is that it used the Pushbullet service which, while great, is not under my control.
I've been running a Matrix chat server at home for a while now. I primarily use it to chat with people in my household in IRC channels. I use a really nice client for Matrix called Riot, which runs in the browser, but is also available on Android and iOS, and is capable of sending notifications about chat events, which I have found really handy.
Recently, I've added a chatbot to my Matrix server named Hubot, thanks to the Hubot-Matrix adapter. Hubot is super neat because it is fairly easy to script up new behaviors, and it has nice built-in support for the web - both for making web requests, but Hubot also runs a server for accepting web requests. Once I realized this, it occurred to me that I could replace my previous notification system that uses Pushbullet with one that goes through Hubot.
First, a note on security. Exposing a chatbot's HTTP listener interface to the great wide internet comes at some risk! I made sure to the following:
-
I run Hubot behind a firewall, so no plain HTTP traffic can come directly across the internet.
- Using another home server, I set up nginx to act as a secure HTTPS proxy, using a certificate from Let's Encrypt to encrypt all traffic that goes over the internet.
- I decided that any behaviors I write for Hubot that use the HTTP listener will use some kind of secret token to ensure that the request is valid. I don't want spammers blowing up my chatrooms!
I decided that the bot should:
-
Allow a user to request webmention.io notifications for a given site into any room.
- Generate and store a "callback secret" to work with webmention.io's Web Hook system and tell the user the URL and callback secret to configure over on the Webmention.io Dashboard.
- Accept HTTP requests from webmention.io at something like <HUBOT_HOST>/hubot/wmio/notify
- Verify that the request contains the callback secret
- Generate a nice text summary of the notification based on its contents
- Send the notification to the room that the user was in when they made the follow request.
With that in mind, I began learning lots about testing Hubot scripts, refreshing myself on Coffeescript, and so on.
I am now happy to introduce this first (janky) release of my Hubot Script, hubot-webmentionio-notify!
Once installed, you can start a conversation with your hubot and ask it to follow a site:
you> hubot wmio follow mycoolsite.biz
hubot> @you OK! Use this as your Web Hook: <HUBOT_URL>/hubot/wmio/notify And use this as your callback secret: 1a2b3c4d5e6f7890000
The string "mycoolsite.biz" can actually be anything and should be something easy to remember in case you want to unfollow notifications later. Hubot doesn't check incoming mentions against it at the moment.
You can enter the URL and callback secret in the Webmention.io dashboard, and future webmentions will be sent to your Hubot and output into the room of your choice.
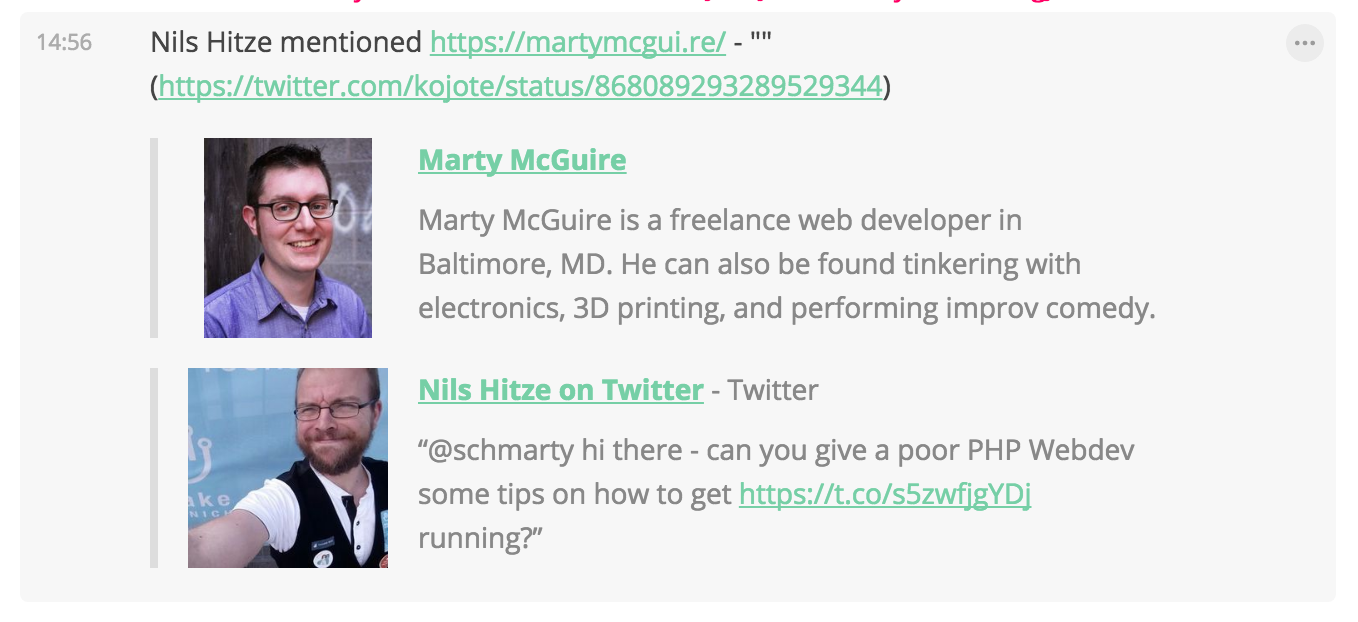
I don't know how useful hubot-webmentionio-notify will be for other folks at the moment, but I am excited be getting these notifications via services that I control. I look forward to building more fun things with Hubot!