IndieWeb dev note: Microsub isn't a general-purpose storage API
This is probably relevant only to very few people and likely only for myself the next time I think up an idea along these lines.
Obligatory background
I'm a heavy daily user of IndieWeb-style social readers. For my setup, I run my own copy of Aaron Parecki's Aperture, a backend service which manages my subscriptions, fetches feeds, and organizes everything into "channels". On my reading devices, I use an app like Aaron Parecki's Monocle, which talks to Aperture to fetch and display my channels and the entries for each, mark things as read, and more.
These tools speak a protocol called Microsub, which defines a simple HTTP protocol for all those things Monocle does. It specifies how a client can ask a server for channels, list entries in a channel, mark things as read, delete things, add new subscriptions, and so on.
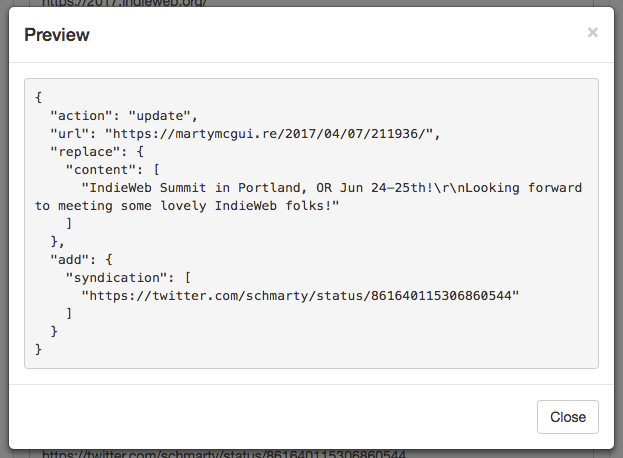
One bonus feature that Aperture has, but that is not part of the Microsub (with an "s") spec, is that in addition to subscribing to feeds, you can also push content into channels, using a different protocol called Micropub, Though they are off by one letter, they do very different things! Micropub (with a "p") is a specification for authoring tools to help you make posts to your personal site, with extensions that also allow for searching posts, updating content, and much more. In Aperture's case, Micropub support is quite minimal - it can be used to push a new entry into a channel, and that's it. It's designed for systems that might not have a public feed, or that create events in real time.
Okay but what's the problem?
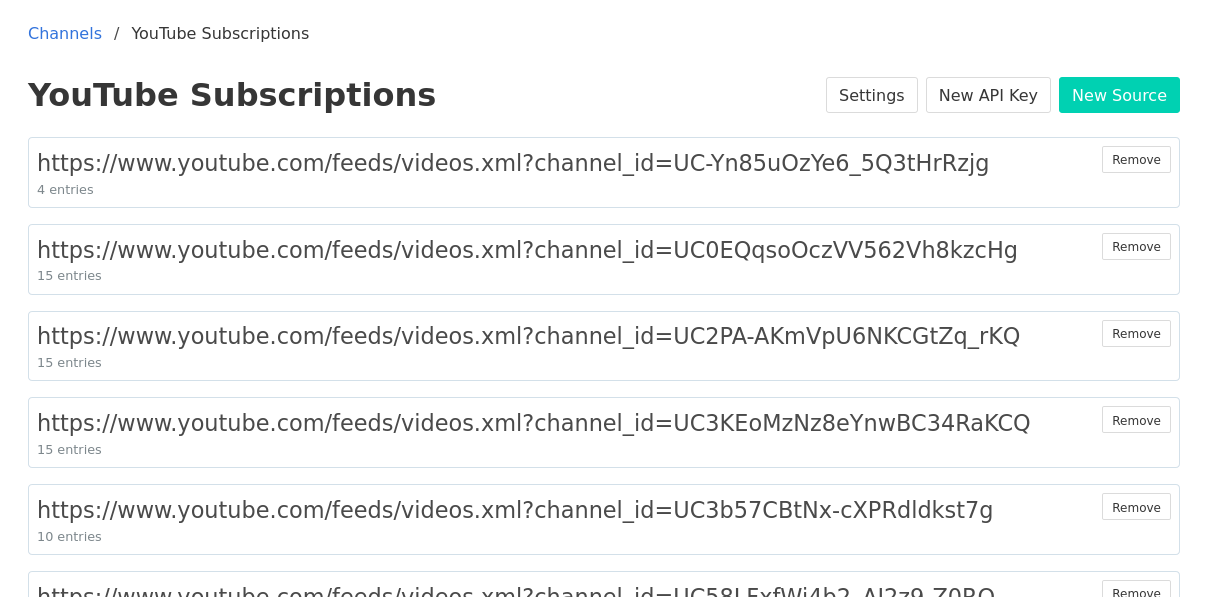
I use Aperture to follow some YouTube channels, so I don't have to visit the distraction-heavy YouTube app to see when my favorite channels update. This is possible because every YouTube channel has an RSS feed! What matters is that a good feed reader can take the URL for a YouTube channel (like the one for IndieWebCamp on YouTube) and parse the page to find its feed (in this case, https://www.youtube.com/feeds/videos.xml?channel_id=UCco4TTt7ikz9xnB35HrD5gQ).
YouTube also provides feeds for playlists, and maybe more! It's a fun way to pull content, and they even support push notifications for these feeds via a standard called WebSub .
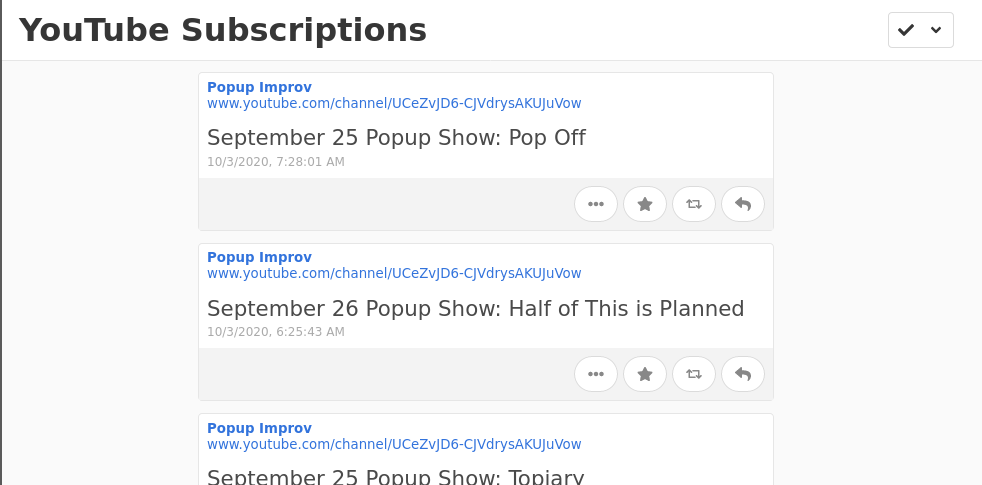
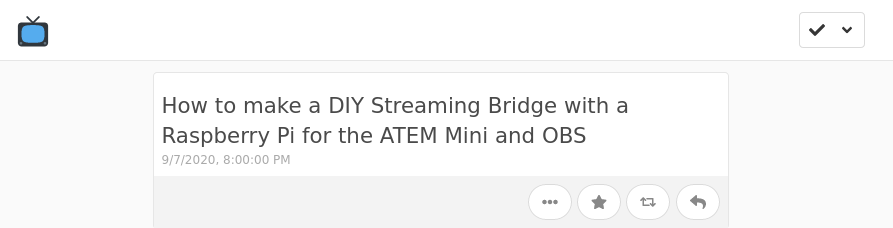
But! (of course there's a but!) YouTube's feeds encode some useful information, like the URL for a video's thumbnail image, and the description for the video, using an extension of RSS called Media RSS. This isn't recognized by Aperture, and it also isn't recognized by my go-to feed munging service Granary. As a result, while I can see when a new video is posted by the channels I follow, they... don't look like much!
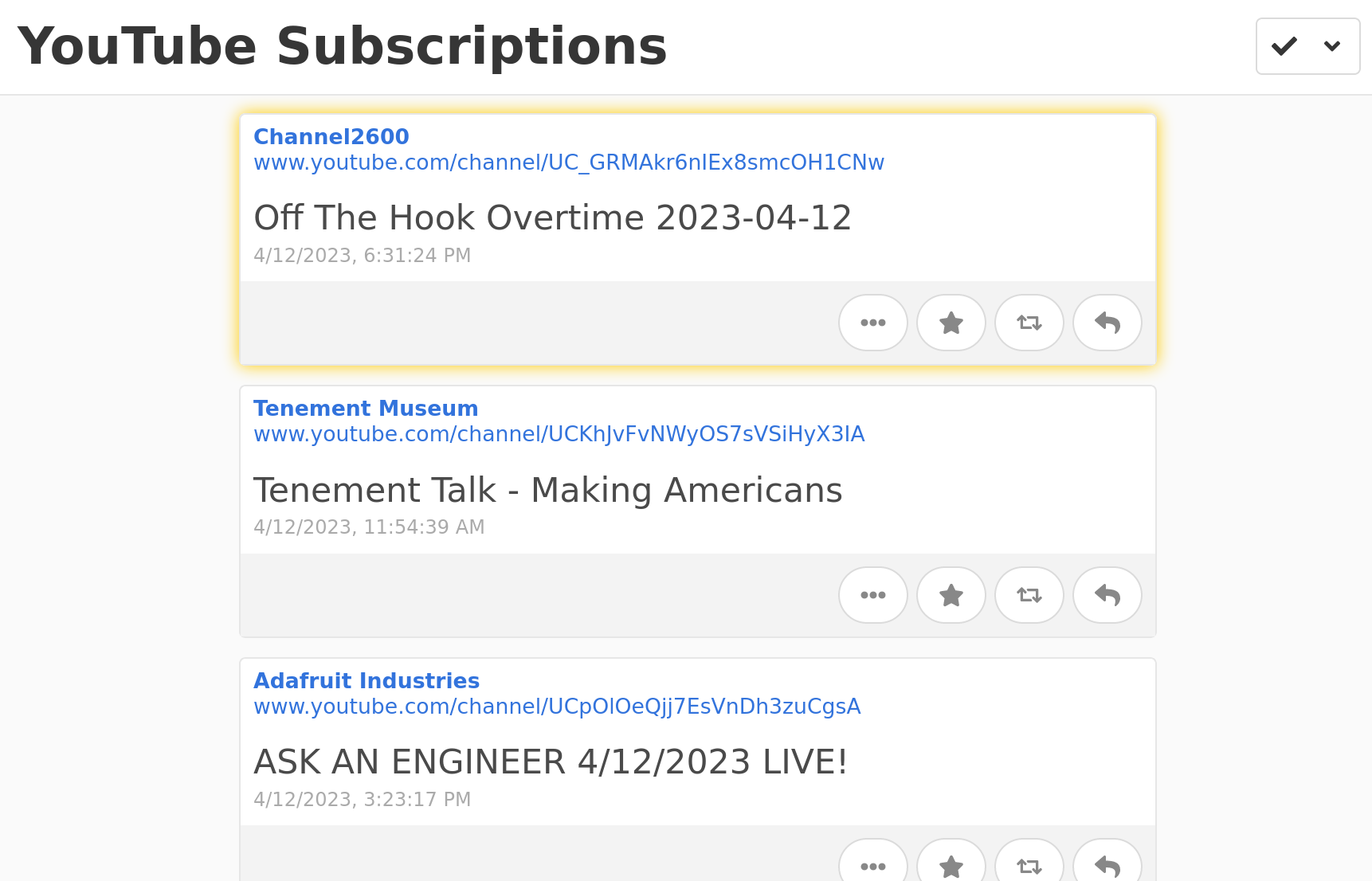
All I can see is that a given channel posted a video, and the title of the video.
Okay can we get to the point?
I'd like to fix this, and my first (wrong) thought was: since Aperture already has these not-very-good entries, maybe I can make an automated system that:
- acts like a Microsub client to fetch each entry from my YouTube Subscriptions channel
- look at each to see if it's missing information like the thumbnail
- for each entry with missing info, look up that info directly from YouTube, maybe via their API
- somehow update the entry with this info.
Again, this is ... the wrong mental model. But why? The docs for Aperture, the Microsub backend, gives us a hint when it covers how to write Microsub clients.
Aperture has implemented the following actions in the Microsub spec:
- GET action=timeline - retrieve the list of items in a channel
- POST action=timeline - mark entries as read, or remove an entry from a channel
- POST action=search - search for a new feed to add
- GET action=preview - preview a feed before following it
- GET action=follow - retrieve the list of feeds followed in a channel
- POST action=follow - follow a new feed in a channel
- POST action=unfollow - unfollow a feed in a channel (existing items from that feed are left in the channel, like IRC/Slack)
- GET action=channels - retrieve the list of channels for a user
- POST action=channels - create, update, and delete channels, or set the order of the channels
Nowhere in that list is the ability to update or even create entries. Those things are outside the scope of the spec. The spec is intentionally narrow in describing how clients can manage channels, subscriptions, and mark read or delete entries pulled from those subscriptions. That's it! And that's good!
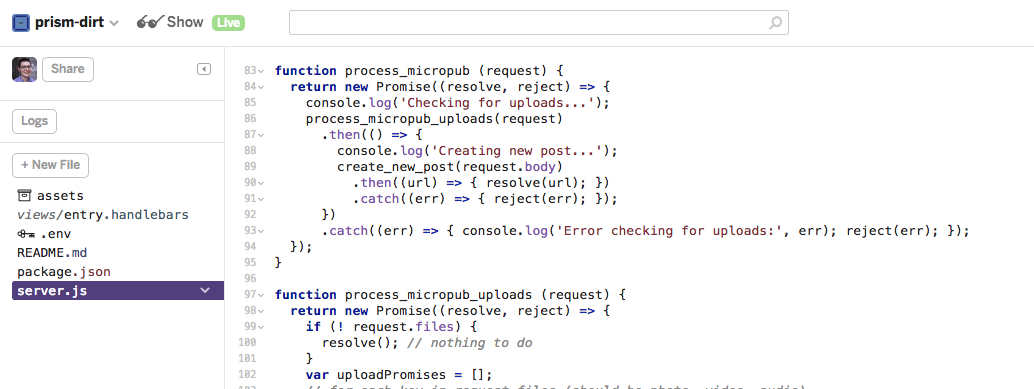
Remembering that the "write API" I was thinking of was actually Micropub (with a "p"), I took a look at the source for Aperture that handles Micropub requests and it does refreshingly few things. It allows creating new entries from a Micropub payload, and it supports uploading media that would go along with a payload. That's it. And that's good!
At this point, I thought I could still continue down my wrong-idea road. The automated system would:
- act as a Microsub (with an "s") client to fetch each entry from my YouTube Subscriptions channel
- look at each to see if it's missing information like the thumbnail
- for each entry with missing info, look up that info directly from YouTube, maybe via their API
- use Microsub to delete the original entry
- use Micropub (with a "p") to create a new entry with all the new details
This approach... should work! However, it certainly felt like I was working against the grain.
I brought this up in the IndieWeb dev chat, where Aaron and Ryan cleared things up. Microsub is intentionally simple, and adding general operations to let clients treat the server like a general data store is way out of scope. Similarly, while Aperture supports some of Micropub, that's a choice specific to Aperture.
Have we learned anything?
The general consensus was that entries should get into a Microsub server like Aperture via feeds. And if the feeds I'm looking at don't have the content I want, I should make a feed that does! I should be able to make a proxy service that:
- accepts a URL for a YouTube channel or playlist feed,
- fetches the feed,
- extracts everything I want from each entry, including thumbnails, and maybe even uses the YouTube API to get info like video length,
- rewrites that in a feed format that Aperture likes better. Probably just HTML with microformats2 to make an h-feed
For each of my YouTube subscriptions, I'll swap out the YouTube RSS for the new proxied feed - something that the Microsub API is intended to let me automate.
One thing I mentioned in the chat discussion I linked above: I default to thinking of feed services like this proxy as "public infrastructure" by default - something that has to be on the public web, with all the maintenance and security issues that go along with that.
However, as I self-host my own Aperture instance, I can set up this proxy on the same server and ensure that it only accepts local requests. Fewer public endpoints, fewer problems.
Anyway, maybe I'll get that done and posted about in the near future, but today I just wanted to get these thoughts out of my head and close some tabs!