Unsubscribing from YouTube's recommender
First, some backstory. But feel free to skip to the good stuff!
With topics ranging from media and social critiques, to making and tech topics that I care about, to death itself, regular content from creators that post on YouTube have been a part of my daily life for the last several years.
This is enabled by three main features:
- Subscriptions, to let me check in for new videos from creators I want to follow.
- The Watch Later playlist, to let me save videos I wanted to include in my regular watching.
- A YouTube app connected to my TV to let me play through my Watch Later list.
Over time, I feel that YouTube has been consistently chipping away at this experience for the sake of engagement.
In 2016, when I found the advertisements to be too invasive, I became a paid "YouTube Red" (now YouTube Premium) subscriber. With ads gone, and with so many content creators posting weekly or more, it was easy to let watching videos through YouTube become a regular habit. Turning off and clearing my YouTube viewing history helped mitigate some of the most creepy aspects of the suggestion system, at the cost of being able to track what I'd seen.
This replaced a lot of idle TV watching time. For several years!
"Progress" marches on, however, and the next thing to go was the experience of accessing the Watch Later playlist. I first noticed this after updating to a 4th generation Apple TV. From the (suggestion-cluttered) main screen of the YouTube app, you must make a series of precise swipes and taps down a narrow side menu to "Library", then to "Watch Later", then to the video that you'd like to start. Not long after, I noticed that the YouTube iOS app and the website itself had similarly moved Watch Later behind a "Library" option that was given the smallest of screen real-estate, overwhelmed by various lists of suggestions of "Recommended for You", "Channels You Might Like", and more.
Most recently, I noticed that YouTube has been changing the definition of a "subscription", where the iOS app will show a timeline of text posts and ephemeral "Moments" in between the actual video content that I am trying to see. Or they'll (experimentally?) try to chunk the subscription display by days or weeks.
All the while, this extra emphasis on recommended videos wore me down. I found myself clicking through to watch stuff that I had not planned to watch when sitting down. Sometimes this would be a fun waste of time. Sometimes I'd get dragged into sensationalized news doom-and-gloom. Regardless, I felt I was being manipulated into giving my time to these suggestions.
And hey, it's #Blocktober, so let's see if we can escape the algorithm a bit more.
A Plan
What I would like to achieve is what I described at the top of my post:
- I want a way to check for new videos from creators I follow (no notifications, please).
- I want a way to add those to a list for later viewing.
- I want to view items from that list on my TV.
RSS is (still) not dead
Feeds are already part of my daily life, thanks to an indie social reader setup. I run Aperture, a Microsub server that manages organizing source feeds in various formats, checking them periodically for new content, and processing them into items grouped by channel. I can browse and interact with those items and channels via Microsub clients, like Monocle which runs in the browser and on my mobile devices with an app called Indigenous.Did you know that YouTube provides an RSS feed for every channel? It's true! In fact, if you visit your Subscription manager page, you'll find a link that the bottom to download a file containing the feed URLs for all of your subscriptions in a format called OPML.
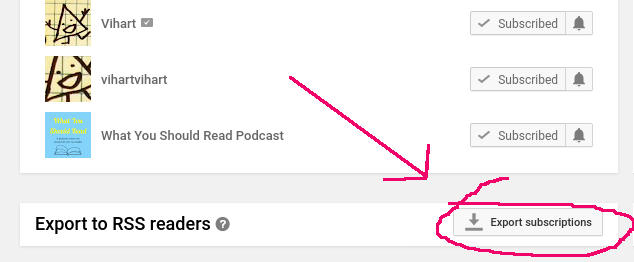
My YouTube subscriptions download had more than 80 feeds (yikes!) so I didn't want to load these into Aperture by hand. Thankfully, there's a command-line tool called ek that could import all of them for me. I had a small issue between ek's expectations and YouTube's subscription file format, but was able to work around it pretty easily. Update 2020-10-04: the issue has already been fixed!
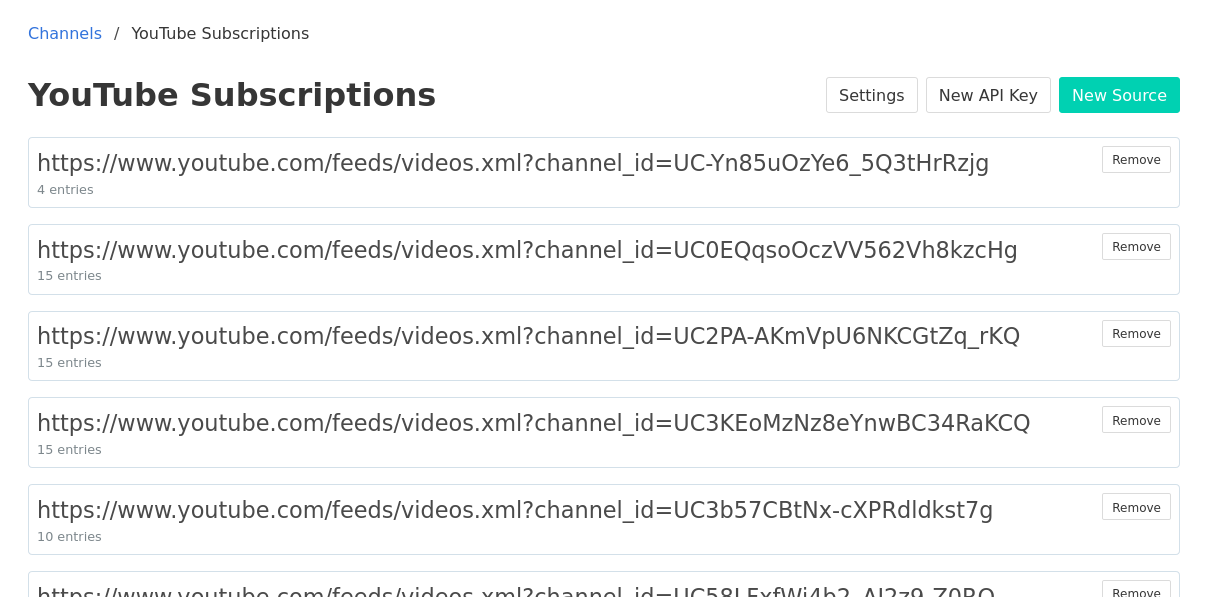
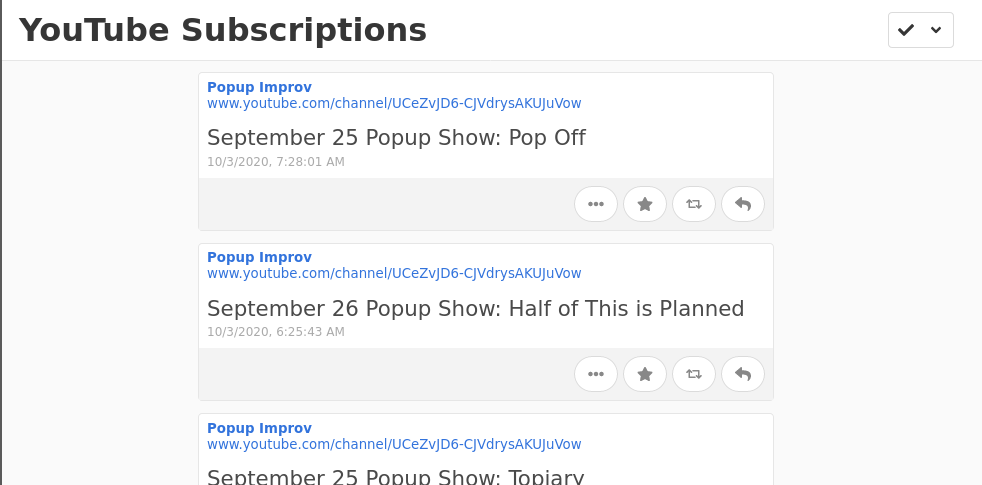
With Aperture taking care of checking these feeds, I can now look at a somewhat minimal listing of new videos from my subscribed channels whenever I want. For any new video I can see the channel it came from, the title of the video, and when it was posted. Importantly, I can click on it to open the video in the YouTube app to watch it right away or save it for later.
This feels like a lot of work to avoid the mildly-annoying experience of opening the YouTube app and browsing the subscriptions page.
We must go further.
Save me (for later)
In addition to fetching and parsing feeds, Aperture also has a bit of a secret feature: each channel has an API, and you can generate a secret token which lets you push content into that channel, via an open protocol called Micropub.
So in theory, I could browse through the list of new videos in my YouTube Subscriptions channel, and — somehow — use Micropub to save one of these posts in a different channel, maybe named Watch Later.
This is where we introduce a super handy service called Indiepaper. It's a bit of web plumbing which essentially takes in a URL, gets all the nice metadata it can figure out (what's the title of this page? who's the author? etc.), and creates a Micropub post about it, wherever you want.
The real ✨magic✨ of Indiepaper comes in the form of utilities that making adding an item as few clicks as possible.
For your desktop web browser, Indiepaper can take your channel's Micropub URL and key and generate a bookmarklet which will send the current page you're looking at straight to your Watch Later channel. Add it to your browser's bookmark toolbar, load a YouTube video, click "Watch Later", and you're done!
For an iOS device, Indiepaper also provides a Shortcut that works the same way. Share a YouTube video URL (from the YouTube app, or straight from your reader) to the Shortcut and it adds the item to the channel right away.
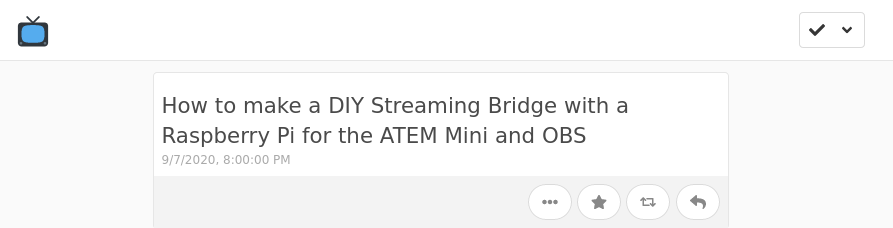
For example, I can load up this YouTube video by Aaron Parecki about making a DIY Streaming Bridge with a Raspberry Pi for the ATEM Mini and OBS in my browser and click the "Watch Later" bookmark in my bookmarks toolbar. After a brief delay, I'll see a notification that it "Saved!", and can check my Watch Later channel (marked with the television emoji 📺) to see that it's there now.
At this point I can:
-
Browse new videos from my subscriptions in my feed reader.
- Save videos on demand to a separate watch later channel in my feed reader
However, something is missing. I still want to be able to watch these, distraction-free, on my TV.
The Last (and Longest) Mile
This is where things get ugly, folks. It is also where I admit that this project is not finished.
As far as I'm aware there are no apps for any "smart" TV or media appliance that can browse a Microsub channel. Much less one that can identify a video URL and send it off to the appropriate app for playback.
However, there are some existing ways to save media on your home network and play it back on your TV, such as Plex or Kodi.
So, here are some highlights:
-
Assuming you've got a Plex server with a library called "myTube". Your TV (maybe through an appliance) can run a Plex app that lets you browse and play that local media distraction-free.
- An automated task on that server could act as a Microsub client, periodically looking in your Watch Later channel for new entries.
- For each new entry, the automated task could fetch the video with a tool like youtube-dl and save it to the myTube folder, where Plex will find it.
Little details:
- To prevent repeated downloads, the automated task should either delete or mark new entries as "read" once they've been downloaded.
-
Plex doesn't have an easy way to delete media from the TV interface. Perhaps the automated task can check with Plex to see if a video has been watched and, if so, remove it from myTube. Or maybe save it to a "watched" list somewhere!
If this feels like a lot of work just to avoid some engagement temptation, that's because it is! It may sound simple to say that someone should build a competitor to YouTube that focuses on creators and viewers. One that doesn't seem to spend all its time pushing ads and pulling on you for engagement and all the other things that go into funding a corporate surveillance-driven behemoth.
But no matter how easy it feels to browse a slickly animated user interface that pushes carefully coached eye-grabbing thumbnails of videos with carefully coached compelling titles, there is a lot about video - even watching video - that is not easy!
It's good to stay mindful of what these services make easy for you, what they make hard, and what they make impossible. Trying to take charge of your own consumption is barely a first step.
What aspects of social media are you shutting down for yourself in #Blocktober?
