Looks like Vimeo is being acquired. To my eyes it appears to be a private equity play by a private equity player with a history of making a mess of their toys.
I know that some folks have seen Vimeo as an alternative to the algorithmic ad-ridden hustle-bustle hell-world that is YouTube. For example, Vi Hart moved all of her 10+ years of YouTube to https://vimeo.com/vihart ! I worry for the future of all those works.
For my part, I uploaded a single video to Vimeo almost 16 years ago to see if it would be a suitable place to post video for sharing to the social networks I was on at the time. I guess I didn’t love it. I’ve now mirrored that single video to my own site. No big deal: MakerBot #131 printing bike handlebar mount bottom
With IndieWeb building blocks like IndieAuth and Micropub, it's more or less possible to create Shortcuts do post any content you want to your personal site, mixing in images and video, and a lot more, all without needing third party apps running on your phone - or even in a browser!
The most important IndieWeb shortcut in my life the last couple of years is the one with which I have posted an animated cat photo to my site every day. In my phone's Photos app I would choose a Live Photo and make sure it's set to Bounce or (less likely) Loop, which will allow it to be shared as a video, then I'd use the Photos app Share function to send it to my Video Micropub shortcut. It would:
Prompt me for a caption for the video and a tag for the post
Post it to my site via Micropub where it will show up in few moments.
I've always found the Shortcut construction UI to be fiddly, and in general I find them difficult to debug. However, once a shortcut is working, they usually make my phone an incredibly powerful tool for managing what I share online.
Suddenly iOS 15 broke my Video Micropub with a non-debuggable "there was a problem running the shortcut" error. I've tried common workarounds suggested online, including re-creating the shortcut from scratch multiple times. It chokes at the media upload step every time.
Without this shortcut, I am kind of at a loss for how to post videos from my phone to my site. There are a number of great Micropub clients in the world, but none of them handles video. I've built Micropub clients of my own in the past, but I find it to be a lot of work each time updating things to keep up with changes in specs or library dependencies, and I find that I am not ready to commit to another one at this time.
Bizarrely, I have a different shortcut, probably thanks to Rosemary or Sebastiaan, which does allow me to upload files to my media endpoint, and get the resulting URL.
I combined that with a very quick and very dirty Secret Web Form that allows me to paste in the URL for the uploaded video, creating a Caturday post.
It's certainly more steps, but at least it's doable from my phone once again.
... or it would be if my phone was creating web-compatible videos!!!
For several versions of iOS (maybe starting with 12?), a new system default was introduced that greatly improved the efficiency with which photos and videos are stored on iOS devices. This is done by using newer and more intensive codecs to compress media files: HEIC for images, and HEVC for video. It turns out that these are not codecs commonly available in web browsers. You can work around this by changing a system-wide setting to instead save images and video in the "Most Compatible" formats - JPEG and MP4 (with video encoded as h264).
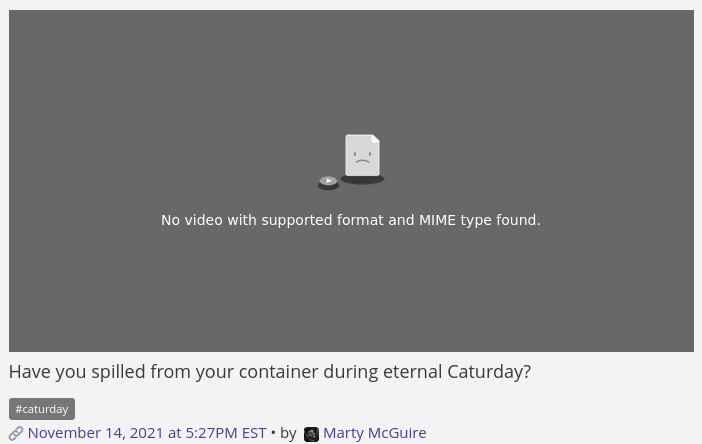
I'm not sure where the root of this change comes from, but for some of my Live Photos, making them a Loop or Bounce video creates an HEVC video and the only working shortcut I have to uploading them to my site takes them as-is. The result is a caturday post that doesn't play!
"No video with supported format and MIME type found" does not spark caturday joy.
So let us arrive at last to the day-saving mentioned in the title of this post.
I'm a big fan of the IndieWeb building block philosophy - simplified systems with distinct sets of responsibilities which can be composed to create complex behaviors using the web as glue. For example, the Micropub spec defines media endpoints with very few required features. The main one: allow a file to be uploaded and to get back a URL where that file will be available on the web.
The spec doesn't say anything about how to handle specifics that might be important. For example, an image on my phone may be a hefty 4 or 5 megabyte pixel party, but I don't want to actually display that whole thing on my website!
I could add some special handling to my media endpoint. For example, have it automatically resize images, save them in multiple formats suitable for different browsers, and more.
But I could also slip a service in the middle that uses the raw uploaded files to create exactly the things I want on demand.
This is where image proxies come in. They are web services that let you ask for a given image on the web, but transformed in some ways.
I have used and loved willnorris/imageproxy as a self-hosted solution. I currently use Cloudinary to handle this on my site today. Go ahead and find a still photo on my site, right-click to inspect and check the image URL!
It turns out that with some setup, Cloudinary will do this for smaller video files as well! This post is getting long, so here are the details:
Create an "Auto upload URL mapping". This is kind of like a folder alias that maps a path on Cloudinary to a path on your server. In my case, I made one named 'mmmgre' which maps to https://media.martymcgui.re/
Update your site template to rewrite your video URLs to fetch them from Cloudinary.
That's it!
So, for example, this video is a .mov file uploaded from my phone, encoded in HEVC: https://media.martymcgui.re/0d/93/a0/f1/be676103d289914ba9660cb8ba0eca2cb87a95c801d750ffc00bbfae.mov
The resulting Cloudinary URL is: https://res.cloudinary.com/schmarty/video/upload/vc_h264/mmmgre/0d/93/a0/f1/be676103d289914ba9660cb8ba0eca2cb87a95c801d750ffc00bbfae.mov
Cloudinary supports a lot of transformations in their URLs, which go right between the `video/upload/` bit and the auto-upload folder name (`/mmmgre/...`). In this case the only one needed is `vc_h264` - this tells Cloudinary to make this video encoded with h264 - exactly what I wanted.
And so, at last, I can post videos from my phone to my website again at last. The world of eternal Caturday is safe... for now.
... or it would be if I didn't need an extra step to ensure that my media upload shortcut actually sends the _video_ instead of a `.jpg`! I'm currently using an app called Metapho to extract the video in a goofy way that works for now but this stuff is mad janky y'all.
In the future:
I'd rather be hosting this myself, but since I'm already using Cloudinary and these Live Photo-based videos are very small, this was a huge win for time-spent-hacking.
Of course I'd much rather overall just have my friggin' shortcut friggin' working again, sheesh.
There has been some chatter in the IndieWeb chat about different approaches to handling video content and posts in Micropub clients. I may join in!
“This is the story of the birth of the web, its loss of innocence, its decline, and what we can do to make it a bit less gross. Or if you prefer, this is the video in which I say the expression “barbecue sets” far too many times.”
After the 2017 IndieWeb Summit, each episode of the podcast also featured a brief ~1 minute interview with one of the participants there. As a way of highlighting these interviews outside the podcast itself, I became interested in the idea of "audiograms" – videos that are primarily audio content for sharing on platforms like Twitter and Facebook. I wrote up my first steps into audiograms using WNYC's audiogram generator.
While these audiograms were able to show visually interesting dynamic elements like waveforms or graphic equalizer data, I thought it would be more interesting to include subtitles from the interviews in the videos. I learned that Facebook supports captions in a common format called SRT. However, Twitter's video offerings have no support for captions.
Thankfully, I discovered the BBC's open source fork of audiogram, which supports subtitles and captioning, including the ability to "bake in" subtitles by encoding the words directly into the video frames. It also relies heavily on BBC web infrastructure, and required quite a bit of hacking up to work with what I had available.
The BBC Audiogram captioning interface.
In the end, my process looked like this:
Export the audio of the ~1 minute interview to an mp3.
Type up a text transcript of the audio. Using VLC's playback controls and turning the speed down to 0.33 made this pretty easy.
Use a "forced alignment" tool called gentle to create a big JSON data file containing all the utterances and their timestamps.
Use the jq command line tool to munge that JSON data into a format that my hacked-up version of the BBC audiogram generator can understand.
Use the BBC audiogram generator to edit the timings and word groupings for the subtitles and generate the final video.
Bonus: the BBC audiogram generator can output subtitles in SRT format - but if I've already "baked them in" this feels redundant.
You can see an early example here. I liked these posts and found them easy to post to my site as well as Facebook, Twitter, Mastodon, etc. Over time I evolved them a bit to include more info about the interviewee. Here's a later example.
One thing that has stuck with me is the idea that Facebook could be displaying these subtitles, if only I was exporting them in the SRT format. Additionally, I had done some research into subtitles for HTML5 video with WebVTT and the <track> element and wondered if it could work for audio content with some "tricks".
TL;DR - Browsers will show captions for audio if you pretend it is a video
Let's skip to the end and see what we're talking about. I wanted to make a version of my podcast where the entire ~10 minutes could be listened to along with timed subtitles, without creating a 10-minute long video. And I did!
How does it work? Well, browsers aren't actually too picky about the data types of the <source> elements inside. You can absolutely give them an audio source.
Add in a poster attribute to the <video> element, and you can give the appearance of a "real" video.
And finally, add in the <source> element with your subtitle track and you are good to go.
The relevant source for my example post looks something like this:
Use the <track> element for your captions/subtitles/etc.
But is that the whole story? Sadly, no.
Creating Subtitles/Captions in WebVTT Format
In some ways, This Week in the IndieWeb Audio Edition is perfectly suited for automated captioning. In order to keep it short, I spend a good amount of time summarizing the newsletter into a concise script, which I read almost verbatim. I typically end up including the transcript when I post the podcast, hidden inside a <details> element.
This script can be fed into gentle, along with the audio, to find all the alignments - but then I have a bunch of JSON data that is not particularly useful to the browser or even Facebook's player.
Thankfully, as I mentioned above, the BBC audiogram generator can output a Facebook-flavored SRT file, and that is pretty close.
00:00:02,24 --> 00:00:04,77
While at the 2017 IndieWeb Summit,
00:00:04,84 --> 00:00:07,07
I sat down with some of the
participants to ask:
Into this:
WEBVTT
00:00:02.240 --> 00:00:04.770
While at the 2017 IndieWeb Summit,
00:00:04.840 --> 00:00:07.070
I sat down with some of the
participants to ask:
Yep. When stripped down to the minimum, the only real differences in these formats is the time format. Decimals delimit subsecond time offsets (instead of commas), and three digits of precision instead of two. Ha!
The Future
If you've been following the podcast, you may have noticed that I have not started doing this for every episode.
The primary reason is that the BBC audiogram tool becomes verrrrry sluggish when working with a 10-minute long transcript. Editing the timings for my test post took the better part of an hour before I had an SRT file I was happy with. I think I could streamline the process by editing the existing text transcript into "caption-sized" chunks, and write a bit of code that will use the pre-chunked text file and the word-timings from gentle to directly create SRT and WebVTT files.
Additionally, I'd like to make these tools more widely available to other folks. My current workflow to get gentle's output into the BBC audiogram tool is an ugly hack, but I believe I could make it as "easy" as making sure that gentle is running in the background when you run the audiogram generator.
Beyond the technical aspects, I am excited about this as a way to add extra visual interest to, and potentially increase listener comprehension for, these short audio posts. There are folks doing lots of interesting things with audio, such as the folks at Gretta, who are doing "live transcripts" with a sort of dual navigation mode where you can click on a paragraph to jump the audio around and click on the audio timeline and the transcript highlights the right spot. Here's an example of what I mean.
I don't know what I'll end up doing with this next, but I'm interested in feedback! Let me know what you think!
Richard, it's early, but at last weekend's IndieWeb Summit in Portland, a small group of us started tinkering on what we hope could be the Timeline of the Open Web.
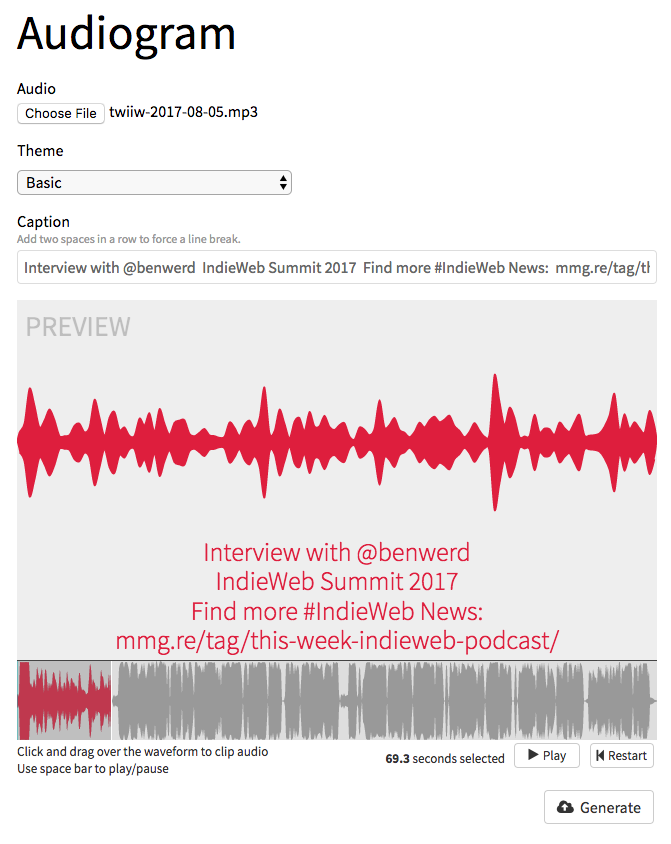
Enter the Audiogram Generator, an open source project that runs on NodeJS and uses FFMPEG to take samples from your audio files and munge them into short videos for sharing on social networks.
Here's a quick rundown of how I got the Audiogram Generator running on my macOS laptop using Docker.
I use Homebrew, so first I installed docker and docker-machine and created a new default machine:
I don't yet know exactly how I'll choose what portions to share on each silo, what text and links to accompany them to encourage folks to listen to the full episodes, and so on. There are also some quirks to learn. For example, Twitter has a maximum length of 2:20 for videos, and its cropping tool would glitch out and reset to defaults unless I stopped it "near" the end.
Thankfully, there is a very detailed Audiogram Generator usage doc with lots of examples and guidelines for making attention-getting posts.
For the near term I want to play with the tool to see what kinds of results I can make. Long-term I think this would be a really neat addition to my Screech tool, which is designed for posting audio to your own website.
How do you feel about audiograms? I'd love to hear other folks' thoughts!
Episode 5 of Lawful & Orderly: Special Visions Unit is now available for watching on YouTube! L&O:SVU is a weekly live-streaming police procedural set in a fantasy universe played (loosely) with D&D 5th Edition rules.