“the design driver for this exercise was to create a solution that allows to embed an (interactive) map where the browser only contacts a third party after informing the user beforehand or – even better – not at all.”
Wonderful post by Sebastian Greger, and right up my alley. I look forward to trying this out with the checkin posts on my site!
Here are some notes from the "broadcast" portion of the meetup:
dariusmccoy.com – Playing with Squarespace because he expects to have youth using it for the upcoming Web Shop launch at DHF. In ~3 weeks! He's trying to clone the existing DHF 3D Print Shop website in it, but finding it a bit restricting. Playing w/ some CodePens for nice animations/transitions but having trouble getting those into the Squarespace editing tools. Wants to use them for within-page links.
derekfields.is – Been struggling w/ goals on personal website stuff. Has been applying for webdev jobs, though! Waiting to hear back. Has been working on his startup idea - an LED backpack for biking. It's controlled by a microcontroller and he wants it to serve a webpage over WiFi so you can control it from your phone without installing anything.
jonathanprozzi.net – Spent time tonight writing a post because he hasn't in a long time. The post includes shaming himself for not writing posts. Writing up his experiences from a recent conference where DHF was receiving an award. Building apps with GatsbyJS which are PWAs that work offline, so the content he writes for DHF can work for people who have viewed them even if the internet goes down.
martymcgui.re – "Launched" his GIPHY-backed GIF posting app Kapowski. After feedback from last time, made it work without requiring logins (making it usable by people who aren't all wired up with IndieAuth on their sites). Thinking about ways to progressively enhance Kapowski, such as saving favorites that can be viewed offline, offline sending with posts going out when the internet comes back, etc. Been going all in on micropub for his personal notes that exist on a private site. Used selfauth, mintoken, skippy's micropub server, spano for media, and built a new nginx auth_request service that uses IndieAuth and an access control list to allow only him to view the private posts. Hoping to clean that up and release it someday soon. Also started first steps for another long-term micropub-related project to assist sites that support micropub for creating and editing posts but don't want to build their own infrastructure for syndication. It's called "POSSE Party", and currently it's a manual-til-it-hurts Micropub editor that lets you manage mp-syndicate-to and syndication properties for posts. Someday he hopes to make something that can use bridgy or silo.pub to automate syndication for people whose sites don't do that.
Other discussion:
LED mounting strategies for backpacks. Big diffusers make for good looking LEDs but surface mount parts make things easier to mount.
Jonathan's experiences at the conference. His takeaways from talks about making human-centered technology. E.g. "context is everything, a perfectly engineered span is useless, but the Brooklyn bridge connects people". He's thinking a lot about common themes around technology that works *for* humans. For example, so many people don't have internet all the time!
Marty and Jonathan chat about the happenings of Memorial Day weekend. Jonathan discusses attending his first game of the season for the Baltimore Brigade. Marty gives the run down on Baltimore's Sandlot.
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
Feeling pretty empowered by understanding more of the nuts-and-bolts of working with SVGs. Inspires me to work on improving my design skills and sensibilities.
Marty and Jonathan finally look to the stars to bring Jeff Goldblum and Dame Judi Dench together. What do their birth signs tell us about their connect? Is Mercury the answer to the problem?
“It is common to refer to universally popular social media sites like Facebook, Instagram, Snapchat, and Pinterest as “walled gardens.” But they are not gardens; they are walled industrial sites, within which users, for no financial compensation, produce data which the owners of the factories sift and then sell. Some of these factories (Twitter, Tumblr, and more recently Instagram) have transparent walls, by which I mean that you need an account to post anything but can view what has been posted on the open Web; others (Facebook, Snapchat) keep their walls mostly or wholly opaque. But they all exercise the same disciplinary control over those who create or share content on their domain.”
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
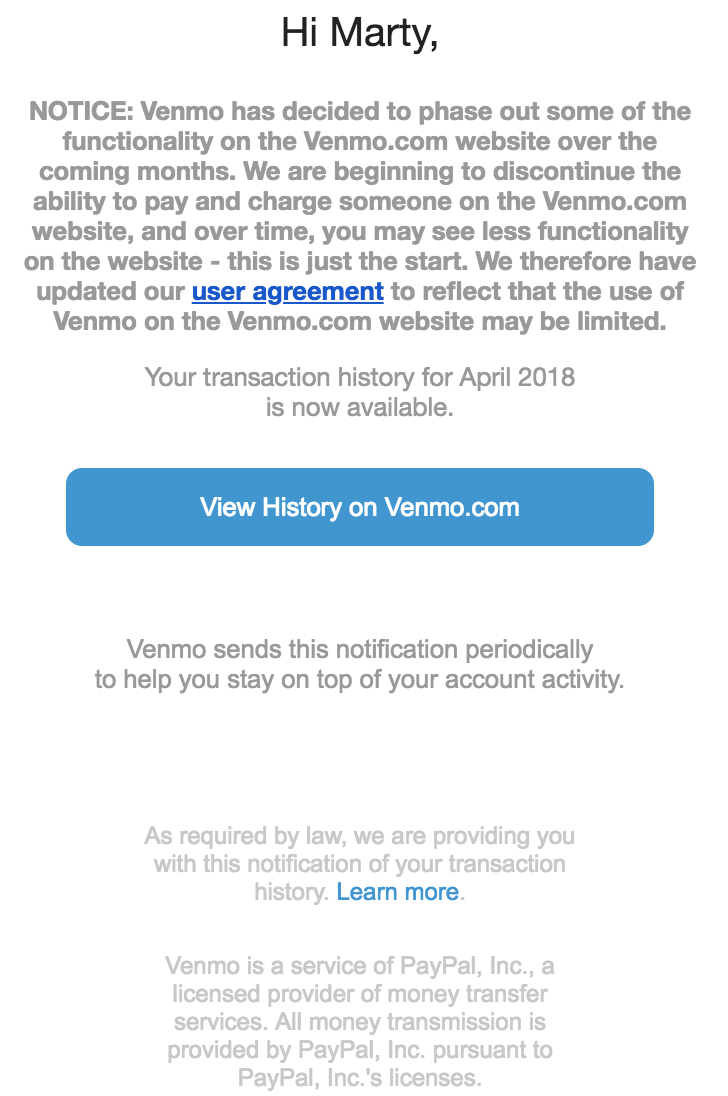
Venmo announces they are removing features from their website over the coming months. The new usage policy literally includes the phrase “We updated our User Agreement to reflect that the use of Venmo on the Venmo.com website may be limited.”
Feels like a standard “silo’s gonna silo” moment, locking people into a mobile app versus making data available on the web. I do wonder how, if at all, it might be related to the requirements of GDPR.
A great intro to the power of service workers, a great collection of resources for learning more, and a great inspiration for improving the things I build on the web!
Update! Due to an internet outage at the venue, and an active Flash Flood Watch
with thunderstorms slated to start right around our meeting time, this HWC has
been cancelled.
See you again on May 29th!
Reminder: We are now meeting on Tuesdays instead of the usual Wednesdays. Be sure to double-check your calendars!
Join us for an evening of quiet writing, IndieWeb demos, and discussions!
Create or update your personal web site!
Finish that blog post you’ve been writing, edit the wiki!
Demos of recent IndieWeb breakthroughs, share what you’ve gotten working!
Join a community with like-minded interests. Bring friends that want a personal site!
Marty and Jonathan prepare for the most important jewel in the Triple Crown. From what to wear, drink, and do they find out what the Preakness is really all about.
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
“it’s hard to listen to those demos without wondering about how services like Duplex might radically alter the workforce. In other words, whose jobs involve making these kinds of phone calls?”
Marty is back from France and Jonathan is all ears. With summer around the corner, they look at what it takes to have a relaxing stay at summer camp. Find out the best ways to stay cool at night and find the perfect temperature for your showers.
“When implemented with the aim of engaging a diverse range of users during a project, participatory design becomes more political by forcing teams to address weaponised design opportunities during all stages of the process.”
“the problems we face with digital labor and digital utopias are not necessarily simply about the digital but rather about systems and structures that have long been in place”
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
Netflix has been a staple in my life for years, from the early days of mailing (and neglecting) mostly-unscratched DVDs through the first Netflix original series and films. With Netflix as my catalog, I felt free to rid myself of countless DVDs and series box sets. Through Netflix I caught up on "must-see" films and shows that I missed the first time around, discovered unexpected (and wonderfully strange) things I would never have seen otherwise. Countless conversations have hinged around something that I've seen / am binging / must add to my list.
At times, this has been a problem. It's so easy to start a show on Netflix and simply let it run. At home we frequently spend a whole evening grinding through the show du jour. Sometimes whole days and weekends disappear. This be can true for more and more streaming services but, in my house, it is most true for Netflix. We want to better use our time, and avoid the temptation to put up our stocking'd feet, settle in, and drop out.
It's easy enough to cancel a subscription, and even easier to start up again later if we change our minds. However, Netflix has one, even bigger, hook into my life: my data. Literal years of viewing history, ratings, and the list of films and shows that I (probably) want to watch some day. I wanted to take that data with me, in case we don't come back and they delete it.
Netflix had an API, but after they shut it down in 2014, it's so far dead that even the blog post announcing the API shutdown is now gone from the internet.
Despite no longer having a formal API, Netflix is really into the single-page application style of development for their website. Typically this is a batch of HTML, CSS, and JavaScript that runs in your browser and uses internal APIs to fetch data from their service. Even better, they are fans of infinite scrolling, so you can open up a page like your "My List", and it loads more data as you scroll, until you've got it all loaded in your browser.
Once you've got all that information in your browser, you can script it right out of there!
Each of these pages displays slightly different data, in HTML that can be extracted with very little javascript, and each loads more data as you scroll the page until it's all loaded. To extract it, I needed some code to walk the entries on the page, extract the info I want, store it in a list, turn the list into a JSON string, and the copy that JSON data to the clipboard. From there I can paste that JSON data into a data file to mess with later, if I want.
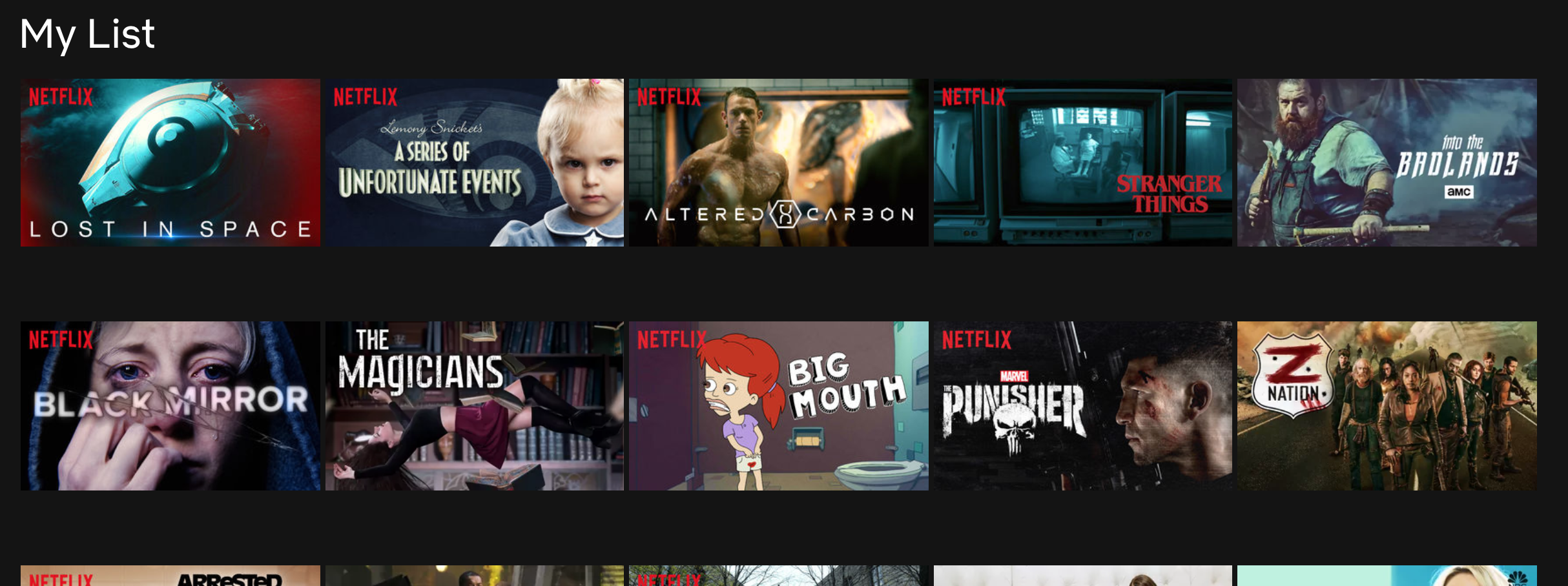
Extracting my Netflix Watch List
A screenshot of my watch list
The My List page has a handful of useful pieces of data that we can extract:
Name of the show / film
URL to that show on Netflix
A thumbnail of art for the show!
After eyeballing the HTML, I came up with this snippet of code to pull out the data and copy it to the clipboard:
I like this very much! I probably won't end up using the Netflix URLs or the art, since it belongs to Netflix and not me, but a list of show titles will make a nice TODO list, at least for the shows I want to watch that are not on Netflix.
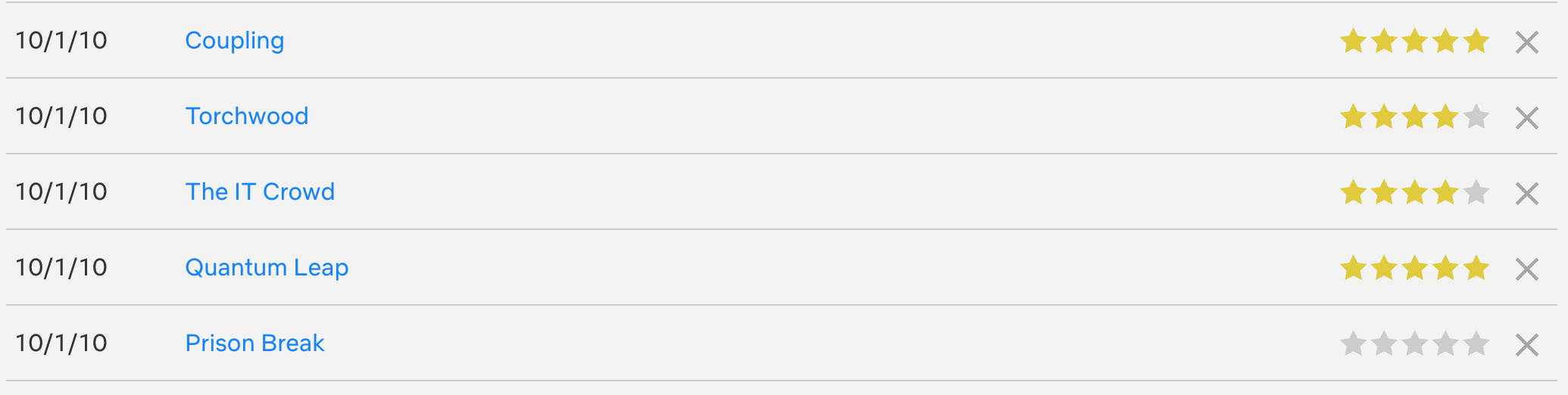
Extracting my Netflix Ratings
A screenshot of my ratings list
More important to me than my to-watch list was my literal years of rating data. This page is very different from the image-heavy watch list page, and is a little harder to find. It's under the account settings section on the website, and is a largely text-based page consisting of:
date of rating (as "day/month/year")
title
URL (on Netflix)
rating (as a number of star elements. Lit up stars indicate the rating that I gave, and these can be counted to get a numerical value of the number of stars.)
The code I used to extract this info looks like this:
While the URL probably isn't that useful, I find it super interesting to have the date that I actually rated each show!
One thing to note, although I wasn't affect by it, Netflix has replaced their 0-to-5 star rating system with a thumbs up / down system. You'd have to tweak the script a bit to extract those values.
Extracting my Netflix Watch History
A screenshot of my watch history page
One type of data I was surprised and delighted to find available was my watch history. This was another text-heavy page, with:
[
{
"date": "3/20/18",
"title": "Marvel's Jessica Jones: Season 2: \"AKA The Octopus\"",
"url": "/title/80130318"
},
...
]
Moving forward
One thing I didn't grab was my Netflix Reviews, which are visible to other Netflix users. I never used this feature, so I didn't have anything to extract. If you are leaving and want that data, I hope that it's similarly easy to extract.
With all this data in hand, I felt much safer going through the steps to deactivate my account. Netflix makes this easy enough, though they also make it extremely tempting to reactivate. Not only do they let you keep watching until the end of the current paid period – they tell you clearly that if you reactivate in 10 months, your data won't be deleted.
That particular temptation won't be a problem for me.
In celebration of 5/01 aka HTTP 501 Not Implemented, we'll talk about things we wish that our websites did, but that they don't yet do.
Here are some notes from the "broadcast" portion of the meetup:
jonathanprozzi.net – Been working on lots of other projects. Did two work projects with GatsbyJS. One is deployed but not public. Learned a lot about GraphQL. Working on a handbook for youth training and trying to get a netlify CMS hooked up to it. Also did a small VueJS project to learn a bit more about it. Wants to use the WordPress API with some of these technologies on his site. 501 desire: going headless for his WordPress site because he is obsessed with PageSpeed.
maryreisenwitz.com – Been working on sites and content for work. Trying to capture FAQs about working at DHF in preparation for a couple of dozen new youth to start working here. Finds that good explanations uncover the need for more good explanations and lots of branching docs, as different youth employees will have different responsibilities. Excited about having this resource be a website. Wants to include a youth "face book" of names and faces so the new folks can recognize one another and existing staff. 501 desire: wants a web store on her main site, because Etsy is becoming frustrating.
bouhmad.com – Set up SSL via LetsEncrypt and loves it, the easiest SSL setup he has ever done. Started a blog post about intrusion detection, kept adding to it, and pushed it out last week. Working on a piece about a bug bounty he recently collected, working with the company in question. 501 desire: a mailing list signup and a Hugo-driven RSS feed to a Mailchimp mailing list.
grant.codes – Visiting as he drives across the US! Restructuring his site's data on the backend. Was using something like mf2 data, but now moving to pure mf2. Broke a bunch of features doing that, so going through to fix those now. 501 desire: homepage mentions! He accepts but doesn't store or display them.
eddiehinkle.com – Working on leaving Facebook! Has made a sign-up form for friends/family to sign up for monthly (for now) newsletter. Has a complex (too complex?) tagging for tech, personal, family to generate three RSS feeds. These can be subscribed to in any combination (so 9 possible feeds), and the emails will combine all posts in the desired feeds. The feeds themselves reuse markup that he wrote to make posts look good on micro.blog. Just posted monthly review for March and hopes to keep doing summaries. Uses the "last month" view on his site for the raw data. 501 desire: automated webmentions! His site is Jekyll-based, so that's a can of worms. Loves using Indigenous for the quick responses from the indie reader, but then has to go back to his site and manually send webmentions.
martymcgui.re – Traveled recently and checked in everywhere using Swarm, which feeds back to his site (sorry anyone following feeds)! Really enjoyed it, but slightly regrets giving Swarm all that data. Thinks an app could use the Swarm venue API to do Micropub and skip creating the checkins on the server. 501 desire: unlisted posts! Really wants to make photo gallery posts where each photo has a permalink but only the gallery shows up in feeds. Eventually private posts, too.
Ways to do hidden posts. Categories. Unlisted or private as a property.
Email lists vs "followers" on social media and the feeling of reach.
Facebook's reaction when you start mass deleting friends. Mary once deleted close to 700 people and found that the interface started rearranging itself, putting people back in the list where it's easy to mis-click and re-add them as a friend.
Deleting your posts from Facebook. Does it affect the algorithm? What threats does it eliminate?
Family signing up for email blasts: would they reply? What if those replies went to an address that turned them into a comment on your site? If their email address is in your nickname cache, you can show their name and photo and url.
“We have a hard time figuring out what Facebook actually is because we have a hard time admitting that at least part of what it supplanted is emotional labor — hard and valuable work that no one wants to admit was work to begin with.”
Marty and Jonathan get to the root of what is growing in our neighborhoods. How are trees picked for a block? Who is planting these trees? Their guest this week has all the answers.