Ah, Vine. I loved the idea of a platform for sharing tiny video moments. It was truly a platform for some really amazing things.
Personally, I didn't make very many posts. Most that I did centered around my involvement with the BlinkyTape Kickstarter that we ran at the height of my awareness of Vine. So, while I had not thought about Vine for quite some time, I was disappointed to hear that it was shutting down the ability to upload.
Announcement like these tend to trigger my site-deaths reflex, so although they have announced plans for some kind of easy export mechanism, I thought: why wait?
This post documents the haphazard, poke-it-with-a-stick-and-see-what-happens method by which I rescued my Vines and their metadata to post them on my own site.
Getting all my Vine URLs
First up, I needed a way to get all of the permalinks to my Vines. The first stumbling block here was that Vine uses an "infinite scroll" technique that shows only the latest vines until you scroll down the page, triggering it to load more for display. Checking out the source of the page, I realized that I could simply scroll to the bottom of my List view to get all the Vine metadata loaded into the page, and I could then open up the Developer Console for Chrome, and drop in a short one-liner to print out all the URLs for my permalinks:
> console.log($('li.permalink a').map((i,el) => el.href));
["https://vine.co/v/hUt0rDdrlK6", "https://vine.co/v/hDIMuqQgtU0", ...
After copying this to a text file and editing out all the quotes and commas, I had a simple text file with the permalink for one of my Vines on each line.
Fetching the HTML
Next up, I grabbed the HTML for each Vine's permalink with a simple script:
#!/usr/bin/env bash
# Usage: ./fetch_htmls.sh < some_file_full_of_vine_urls.txt
while read url
do
# each vine has a unique id after the last '/' character
id=`echo "${url}" | cut -d'/' -f 5`
html_file="htmls/${id}"
if [ ! -f "${html_file}" ]; then
wget -O "${html_file}" "${url}"
sleep 5
fi
done
Extracting the Useful Data
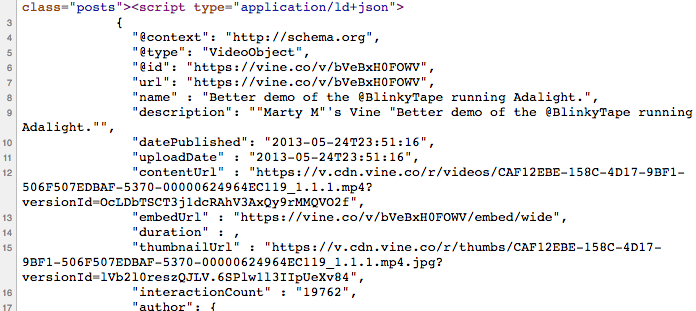
It's often "enough" to have all the HTML on a page - you can write a script to parse the HTML, select out various attributes and text values from the elements on the page, and grab whatever data you need. In the case of Vine, they make it a little easier. Each HTML page has an embedded <script> element in JSON-LD format:
After playing with the data in there a bit, I wrote a quick script using the pup command line tool to do parse the HTML and extract the (valid parts of the) JSON-LD chunks from each HTML page.
#!/usr/bin/env bash
# Usage: ./extract_ld_json.sh htmls/*
# Extract <script type="application/ld+json"> content from Vine
# page, filtering out attributes that are not valid JSON.
#
# - description - invalid quoting and redundant with author and name values
# - duration - invalid non-value
for html_file in "$@"
do
id=`basename "${html_file}"`
jsonld_file="json_lds/${id}"
if [ ! -f "${jsonld_file}" ]; then
pup 'script[type="application/ld+json"] text{}' < "${html_file}" \
| grep -v '"description":' \
| grep -v '"duration" :' \
> "${jsonld_file}"
fi
done
These JSON-LD chunks gave me all the metadata I cared about, including URLs to the media that I wanted to save: the videos, their thumbnail images, and the avatar image that accompanied each post. So, it was time to write tools to extract those, too. One of my recent favorite command line tools is jq aka "sed for JSON", so I used that to extract the URLs I needed to fetch all the media.
The videos:
#!/usr/bin/env bash
# Usage: ./fetch_videos.sh json_lds/*
for jsonld_file in "$@"
do
id=`basename "${jsonld_file}"`
video_file="videos/${id}.mp4"
if [ ! -f "${video_file}" ]; then
video_url=`jq -r '.contentUrl' < "${jsonld_file}"`
wget -O "${video_file}" "${video_url}"
sleep 6
fi
done
The thumbnails:
#!/usr/bin/env bash
# Usage: ./fetch_thumbs.sh json_lds/*
for jsonld_file in "$@"
do
id=`basename "${jsonld_file}"`
thumb_file="thumbs/${id}.jpg"
if [ ! -f "${thumb_file}" ]; then
thumb_url=`jq -r '.thumbnailUrl' < "${jsonld_file}"`
wget -O "${thumb_file}" "${thumb_url}"
sleep 6
fi
done
And finally, the avatars. I really could have just manually saved my one avatar image, but that is not my way. Instead, this script finds every avatar URL, hashes that URL to get a filename-safe name, and fetches it (once):
#!/usr/bin/env bash
# Usage: ./fetch_avatars.sh json_lds/*
for jsonld_file in "$@"
do
avatar_url=`jq -r '.author .image' < "${jsonld_file}"`
id=`echo "${avatar_url}" | shasum - | awk '{ print $1; }'`
avatar_file="avatars/${id}.jpg"
if [ ! -f "${avatar_file}" ]; then
wget -O "${avatar_file}" "${avatar_url}"
sleep 6
fi
done
Finally, it was time to synthesize all of this info to put these Vines on my own site. I currently use Jekyll to generate my website, so I wrote a pair of scripts to convert the JSON-LD data into Jekyll posts. First, a Python script that converts a single Vine into a Jekyll post with YAML metadata:
#!/usr/bin/env python
import json
import sys
import yaml
import os
with open(sys.argv[], 'r') as f:
jsonld = json.load(f, )
vineid = os.path.basename(jsonld['url'])
post_meta = {
'date': jsonld['datePublished'],
'files': [ vineid + ".mp4" ],
'filemeta': {
(vineid + ".mp4"): {
'poster': (vineid + ".jpg")
}
},
'h': 'entry',
'syndication': [ jsonld['url'] ],
'vine_metadata': jsonld,
'updated': jsonld['datePublished']
}
content = jsonld['name']
print "---"
print yaml.safe_dump(post_meta)
print "---"
print ""
print content
And finally a shell script to run the Python converter over each JSON-LD file, save the resulting Jekyll post output in the appropriate place, and copy over the related media assets:
#!/usr/bin/env bash
# Usage ./vines_to_jekyll.sh json_lds/*
BASEDIR=~/me/martymcgui.re
for vine in "$@"
do
vineid=`basename "${vine}"`
vinedate=`jq -r '.datePublished' < "${vine}"`
filename="${BASEDIR}"/_posts/`date -j -f "%FT%H:%M:%S" "${vinedate}" +"%F-%H%M%S"`.md
asset_dir="${BASEDIR}"/_assets/posts/`date -j -f "%FT%H:%M:%S" "${vinedate}" +"%Y/%m/%d/%H%M%S"`
echo "${vine}"
mkdir -p "${asset_dir}"
cp videos/"${vineid}.mp4" "${asset_dir}"
cp thumbs/"${vineid}.jpg" "${asset_dir}"
python vine_to_jekyll.py "${vine}" > "${filename}"
done
At last, I created a Jekyll include to render the Vines out as HTML5 video elements, with the thumbnail as the poster image, visible play controls, and the obligatory feature of looping forever once started. My Jekyll theme is a bit out of scope for this post, but it pretty much looks like this:
{% raw %}{% capture poster %}
{% if include.filemeta and include.filemeta.poster %}
poster="{{ page | asset_path | append: include.filemeta.poster }}"
{% endif %}
{% endcapture %}{% endraw %}
<video loop controls {{ poster }} style="width: 100%">
<source class="u-video" type="video/mp4" src="{{ include.asset }}" />
</video>
What is the end result? How about some example posts?
While I am not particularly happy that Vine is seemingly closing down, I do enjoy data liberation projects like these. I learned a bit about how Vine was built, got to play with some neat tools, and I now own my Vines, having brought them into my own site. While I'm not in control of whether Vine works in the future, I do have control over the future of the videos that I posted there.
Was this useful to you? Let me know! I don't have my #indieweb comments system in place, yet, but you can hit me up on Twitter or Facebook and I'd love to read your thoughts!