“The resulting mess firmly favors attackers (wage stealers, fraudsters, censors, bullies) over defenders (creators, critics). Attackers don’t need to waste their time making art, which leaves them with the surplus capacity to master the counterintuitive “legal” framework.”
Amnesty International (rightly) calls out the damages of surveillance capitalism by Google and Facebook but, ouch, they serve up behavioral trackers for ad networks on their own content. 😩
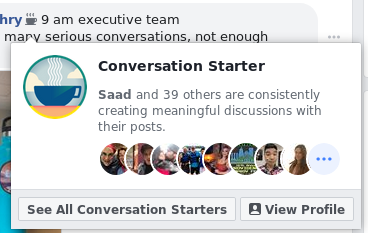
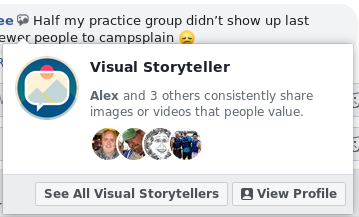
Facebook coming through with some pretty gross new UI changes, now adding little badge icons next to some people’s names indicating that they are a “Conversation Starter”, “Visual Storyteller”, and possibly others.
Really raises some questions for me. Mainly, what are their goals for this “feature”?
To boost engagement of people who want to earn a particular little badge? (“Oh, I’ve got to post more photos!”)
To boost engagement of people who see the badges? (“Ooh, I wanna join in these conversations they’re starting!”)
“It is common to refer to universally popular social media sites like Facebook, Instagram, Snapchat, and Pinterest as “walled gardens.” But they are not gardens; they are walled industrial sites, within which users, for no financial compensation, produce data which the owners of the factories sift and then sell. Some of these factories (Twitter, Tumblr, and more recently Instagram) have transparent walls, by which I mean that you need an account to post anything but can view what has been posted on the open Web; others (Facebook, Snapchat) keep their walls mostly or wholly opaque. But they all exercise the same disciplinary control over those who create or share content on their domain.”
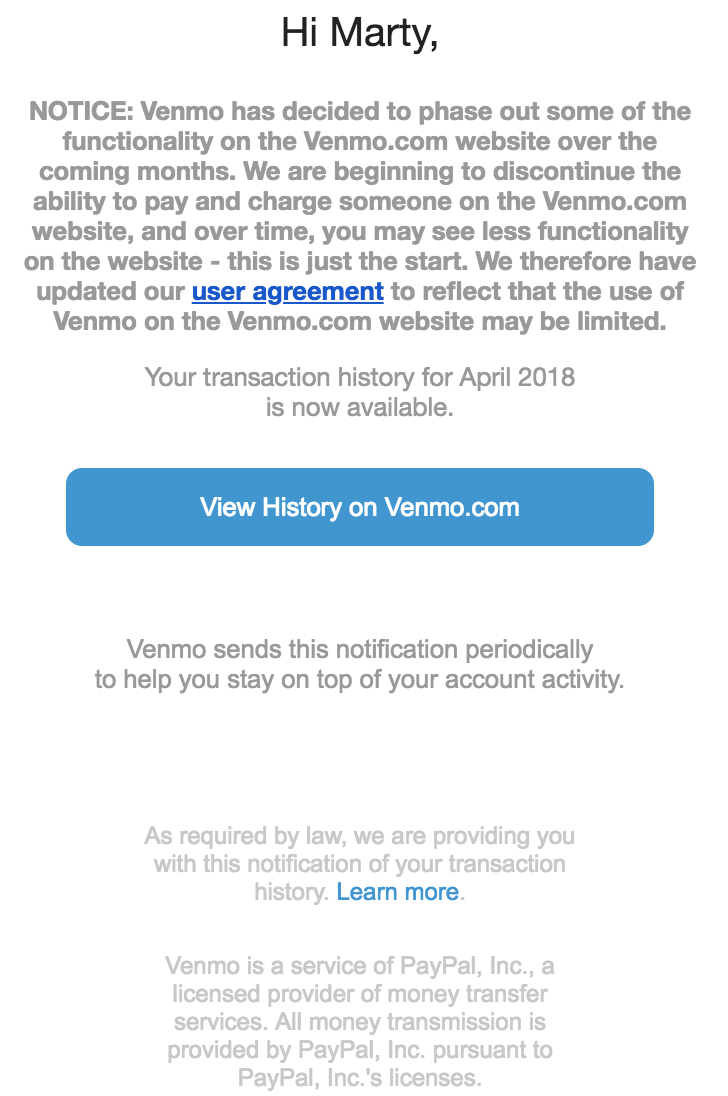
Venmo announces they are removing features from their website over the coming months. The new usage policy literally includes the phrase “We updated our User Agreement to reflect that the use of Venmo on the Venmo.com website may be limited.”
Feels like a standard “silo’s gonna silo” moment, locking people into a mobile app versus making data available on the web. I do wonder how, if at all, it might be related to the requirements of GDPR.
Netflix has been a staple in my life for years, from the early days of mailing (and neglecting) mostly-unscratched DVDs through the first Netflix original series and films. With Netflix as my catalog, I felt free to rid myself of countless DVDs and series box sets. Through Netflix I caught up on "must-see" films and shows that I missed the first time around, discovered unexpected (and wonderfully strange) things I would never have seen otherwise. Countless conversations have hinged around something that I've seen / am binging / must add to my list.
At times, this has been a problem. It's so easy to start a show on Netflix and simply let it run. At home we frequently spend a whole evening grinding through the show du jour. Sometimes whole days and weekends disappear. This be can true for more and more streaming services but, in my house, it is most true for Netflix. We want to better use our time, and avoid the temptation to put up our stocking'd feet, settle in, and drop out.
It's easy enough to cancel a subscription, and even easier to start up again later if we change our minds. However, Netflix has one, even bigger, hook into my life: my data. Literal years of viewing history, ratings, and the list of films and shows that I (probably) want to watch some day. I wanted to take that data with me, in case we don't come back and they delete it.
Netflix had an API, but after they shut it down in 2014, it's so far dead that even the blog post announcing the API shutdown is now gone from the internet.
Despite no longer having a formal API, Netflix is really into the single-page application style of development for their website. Typically this is a batch of HTML, CSS, and JavaScript that runs in your browser and uses internal APIs to fetch data from their service. Even better, they are fans of infinite scrolling, so you can open up a page like your "My List", and it loads more data as you scroll, until you've got it all loaded in your browser.
Once you've got all that information in your browser, you can script it right out of there!
Each of these pages displays slightly different data, in HTML that can be extracted with very little javascript, and each loads more data as you scroll the page until it's all loaded. To extract it, I needed some code to walk the entries on the page, extract the info I want, store it in a list, turn the list into a JSON string, and the copy that JSON data to the clipboard. From there I can paste that JSON data into a data file to mess with later, if I want.
Extracting my Netflix Watch List
A screenshot of my watch list
The My List page has a handful of useful pieces of data that we can extract:
Name of the show / film
URL to that show on Netflix
A thumbnail of art for the show!
After eyeballing the HTML, I came up with this snippet of code to pull out the data and copy it to the clipboard:
I like this very much! I probably won't end up using the Netflix URLs or the art, since it belongs to Netflix and not me, but a list of show titles will make a nice TODO list, at least for the shows I want to watch that are not on Netflix.
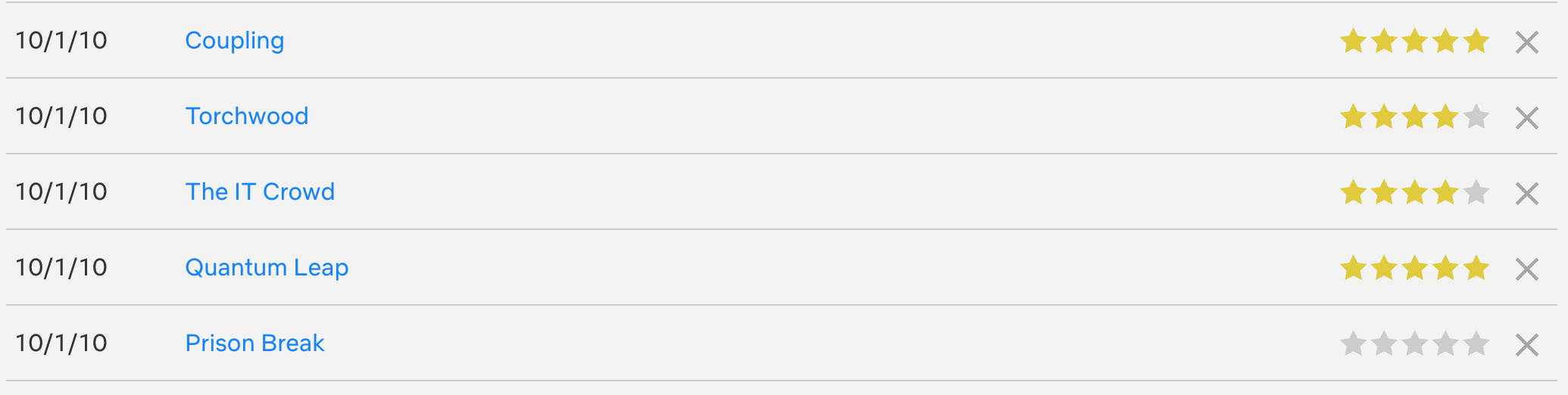
Extracting my Netflix Ratings
A screenshot of my ratings list
More important to me than my to-watch list was my literal years of rating data. This page is very different from the image-heavy watch list page, and is a little harder to find. It's under the account settings section on the website, and is a largely text-based page consisting of:
date of rating (as "day/month/year")
title
URL (on Netflix)
rating (as a number of star elements. Lit up stars indicate the rating that I gave, and these can be counted to get a numerical value of the number of stars.)
The code I used to extract this info looks like this:
While the URL probably isn't that useful, I find it super interesting to have the date that I actually rated each show!
One thing to note, although I wasn't affect by it, Netflix has replaced their 0-to-5 star rating system with a thumbs up / down system. You'd have to tweak the script a bit to extract those values.
Extracting my Netflix Watch History
A screenshot of my watch history page
One type of data I was surprised and delighted to find available was my watch history. This was another text-heavy page, with:
[
{
"date": "3/20/18",
"title": "Marvel's Jessica Jones: Season 2: \"AKA The Octopus\"",
"url": "/title/80130318"
},
...
]
Moving forward
One thing I didn't grab was my Netflix Reviews, which are visible to other Netflix users. I never used this feature, so I didn't have anything to extract. If you are leaving and want that data, I hope that it's similarly easy to extract.
With all this data in hand, I felt much safer going through the steps to deactivate my account. Netflix makes this easy enough, though they also make it extremely tempting to reactivate. Not only do they let you keep watching until the end of the current paid period – they tell you clearly that if you reactivate in 10 months, your data won't be deleted.
That particular temptation won't be a problem for me.
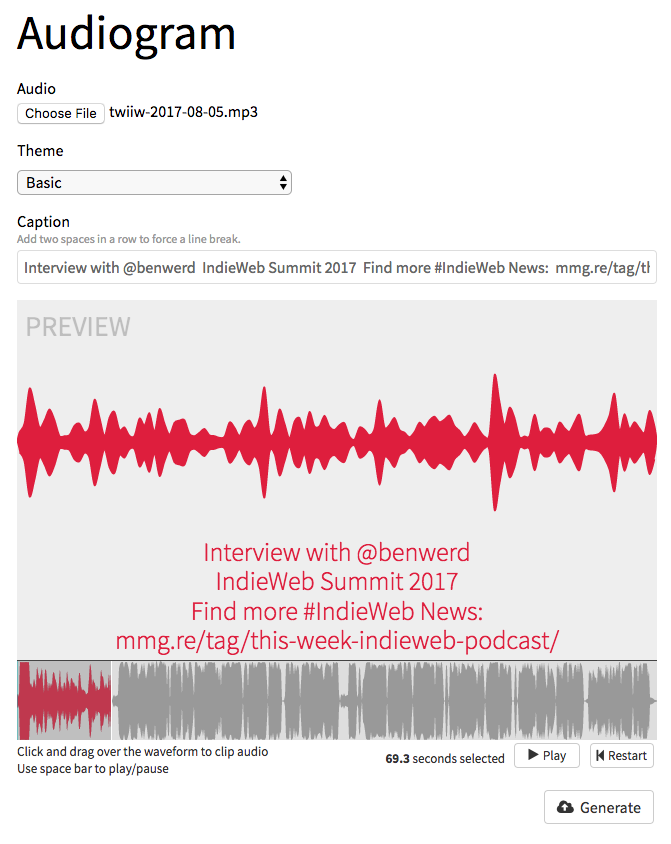
Enter the Audiogram Generator, an open source project that runs on NodeJS and uses FFMPEG to take samples from your audio files and munge them into short videos for sharing on social networks.
Here's a quick rundown of how I got the Audiogram Generator running on my macOS laptop using Docker.
I use Homebrew, so first I installed docker and docker-machine and created a new default machine:
I don't yet know exactly how I'll choose what portions to share on each silo, what text and links to accompany them to encourage folks to listen to the full episodes, and so on. There are also some quirks to learn. For example, Twitter has a maximum length of 2:20 for videos, and its cropping tool would glitch out and reset to defaults unless I stopped it "near" the end.
Thankfully, there is a very detailed Audiogram Generator usage doc with lots of examples and guidelines for making attention-getting posts.
For the near term I want to play with the tool to see what kinds of results I can make. Long-term I think this would be a really neat addition to my Screech tool, which is designed for posting audio to your own website.
How do you feel about audiograms? I'd love to hear other folks' thoughts!
“Silicon Valley brings us the worst of two economic systems: the inefficiency of a command economy coupled with the remorselessness of laissez-faire liberalism.”
Jonathan Prozzi and I have challenged one another to make a post about improving our websites once a week. Here's mine!
Back in 2008 I started a new blog on Wordpress. It seemed like a good idea! Maybe I would post some useful things and someone would offer me a job! I wanted to allow discussion without the dangers of letting strangers submit data directly to my server, so I set up the JavaScript-based Disqus comments service. I made a few posts per year and it eventually tapered off and I largely forgot about it.
In February 2011 I participated in the Thing-a-Day project on Posterous. It was the first time in a long time that I had published consistently, so when it was announced that Posterous was going away, I worked hard to grab my content and stored it somewhere.
Eventually it was November 2013, Wordpress was "out", static site generators were "in", and I wanted to give Octopress a try. I used Octopress' tools to import all my Wordpress content into Octopress, forgot about adding back the Disqus comments, and posted it all back online. In February 2014, I decided to resurrect my Posterous content, so I created posts for it and got everything looking nice enough.
In 2015 I learned about the IndieWeb, and decided it was time for a new approach to my identity and content online. I set up a new site at https://martymcgui.re/ based on Jekyll (hey! static sites are still "in"!) and got to work adding IndieWeb features.
Well, today I decided to get some of that old content off my other domain and into my official one. Thankfully, with Octopress being based on Jekyll, it was mostly just a matter of copying over the files in the _posts/ folder. A few tweaks to a few posts to make up for newer parsing in Jekyll, my somewhat odd URL structure, etc., and I was good to go!
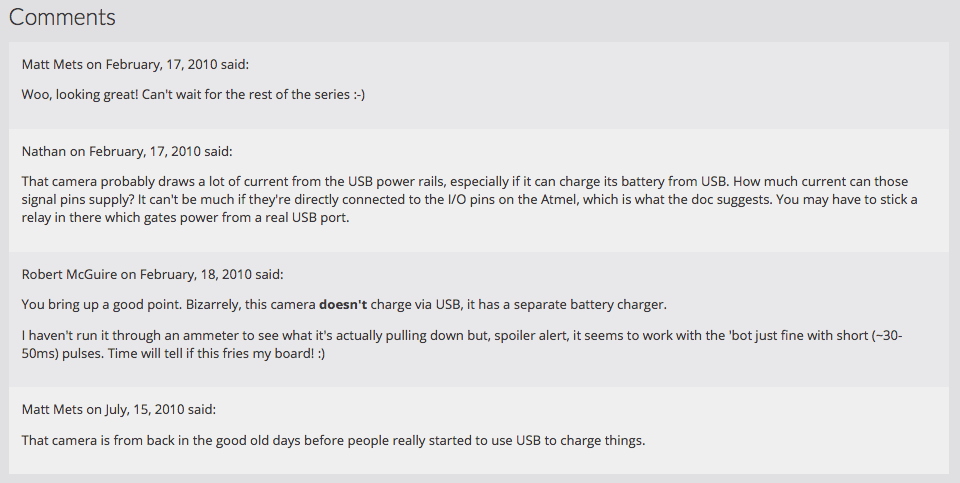
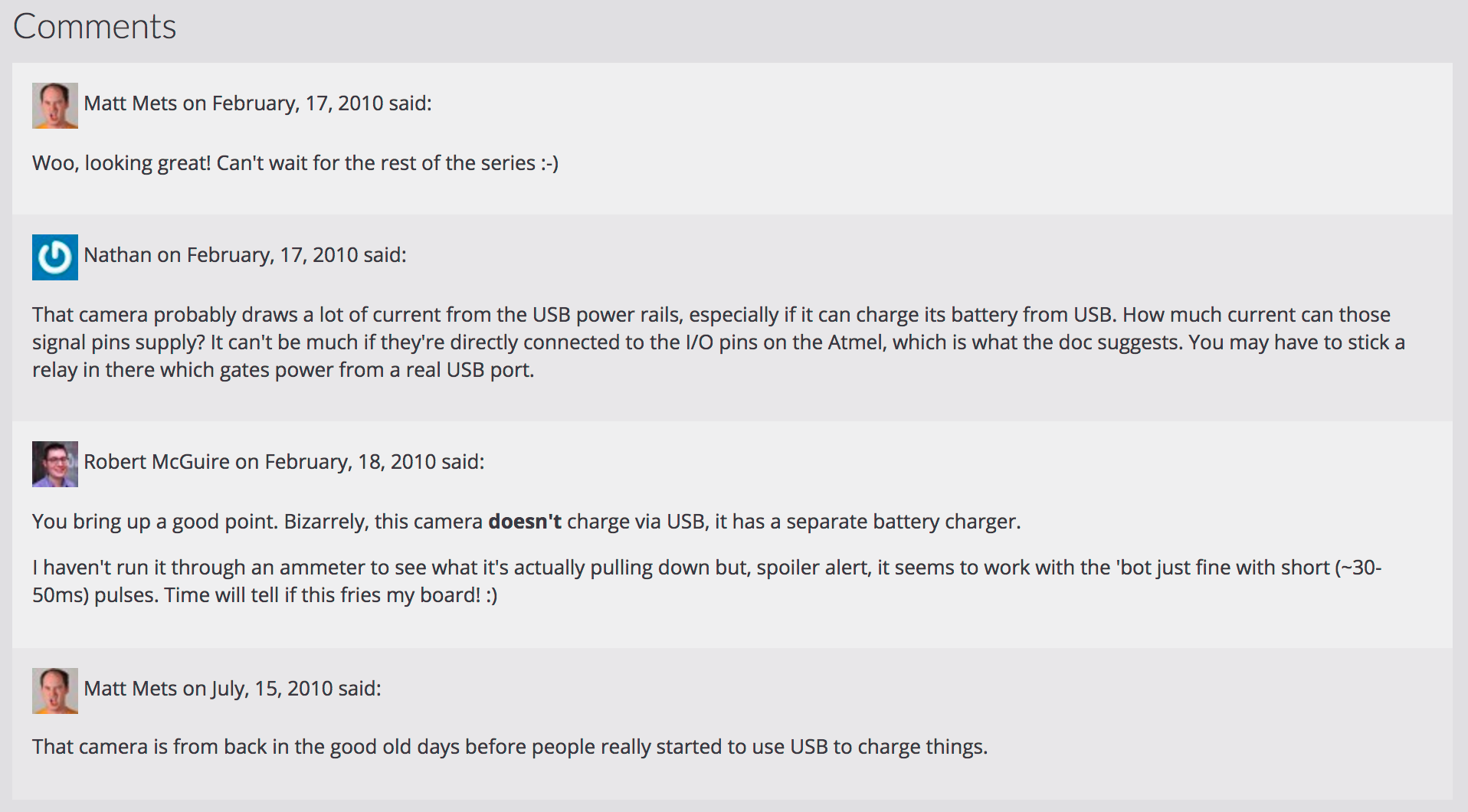
"Owning" My Disqus Comments
Though I had long ago considered them lost, I noticed that some of my old posts had a section that the Octopress importer had added to the metadata of my posts from Wordpress:
All of my Wordpress posts had this dsq_thread_id value, and that got me thinking. Could I export the old Disqus comment data and find a way to display it on my site? (Spoiler alert: yes I could).
You can request a compressed XML file containing all of your comment data, organized hierarchically into "category" (which I think can be configured per-site), "thread" (individual pages), and "post" (the actual comments), and includes info such as author name and email, the date it was created, the comment message with some whitelisted HTML for formatting and links, whether the comment was identified as spam or has been deleted, etc.
The XML format was making me queasy, and Jekyll data files often come in YAML format for editability, so I did the laziest XML to YAML transform possible, thanks to some Ruby and this StackOverflow post.
I dropped this into my Jekyll site as _data/disqus.yml, and ... that's it! I could now access the content from my templates in site.data.disqus.
I wrote a short template snippet that, if the post has a "meta" property with a "dsq_thread_id", to look in site.data.disqus.disqus.post and collect all Disqus comments where "thread.dsq:id" was the same as the "dsq_thread_id" for the post. If there are comments there, they're displayed in a "Comments" section on the page.
So now some of my oldest posts have some of their discussion back after more than 7 years!
I was (pleasantly) surprised to be able to recover and consolidate this older content. Thanks to past me for keeping good backups, and to Disqus for still being around and offering a comprehensive export.
As a bonus, since all of the comments include the commenter's email address, I could give them avatars with Gravatar, and (though they have no URL to link to) they would almost look right at home alongside the more modern mentions I display on my site.