Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
Jonathan Prozzi and I have challenged one another to make a post about improving our websites once a week. This is me getting back on the train!
In a previous site update I wrote about setting up a system to notify me whenever my site received webmentions. Essentially, this meant that I could now get notifications on my phone and desktop whenever somebody interacted with my site, such as: replying to one of my posts on their own site, retweeting or favoriting one of my posts, or even RSVPs to my Facebook events.
One thing I didn't super like about this system is that it used the Pushbullet service which, while great, is not under my control.
I've been running a Matrix chat server at home for a while now. I primarily use it to chat with people in my household in IRC channels. I use a really nice client for Matrix called Riot, which runs in the browser, but is also available on Android and iOS, and is capable of sending notifications about chat events, which I have found really handy.
Recently, I've added a chatbot to my Matrix server named Hubot, thanks to the Hubot-Matrix adapter. Hubot is super neat because it is fairly easy to script up new behaviors, and it has nice built-in support for the web - both for making web requests, but Hubot also runs a server for accepting web requests. Once I realized this, it occurred to me that I could replace my previous notification system that uses Pushbullet with one that goes through Hubot.
First, a note on security. Exposing a chatbot's HTTP listener interface to the great wide internet comes at some risk! I made sure to the following:
I run Hubot behind a firewall, so no plain HTTP traffic can come directly across the internet.
Using another home server, I set up nginx to act as a secure HTTPS proxy, using a certificate from Let's Encrypt to encrypt all traffic that goes over the internet.
I decided that any behaviors I write for Hubot that use the HTTP listener will use some kind of secret token to ensure that the request is valid. I don't want spammers blowing up my chatrooms!
I decided that the bot should:
Allow a user to request webmention.io notifications for a given site into any room.
Generate and store a "callback secret" to work with webmention.io's Web Hook system and tell the user the URL and callback secret to configure over on the Webmention.io Dashboard.
Accept HTTP requests from webmention.io at something like <HUBOT_HOST>/hubot/wmio/notify
Verify that the request contains the callback secret
Generate a nice text summary of the notification based on its contents
Send the notification to the room that the user was in when they made the follow request.
I am now happy to introduce this first (janky) release of my Hubot Script, hubot-webmentionio-notify!
Once installed, you can start a conversation with your hubot and ask it to follow a site:
you> hubot wmio follow mycoolsite.biz
hubot> @you OK! Use this as your Web Hook: <HUBOT_URL>/hubot/wmio/notify
And use this as your callback secret: 1a2b3c4d5e6f7890000
The string "mycoolsite.biz" can actually be anything and should be something easy to remember in case you want to unfollow notifications later. Hubot doesn't check incoming mentions against it at the moment.
You can enter the URL and callback secret in the Webmention.io dashboard, and future webmentions will be sent to your Hubot and output into the room of your choice.
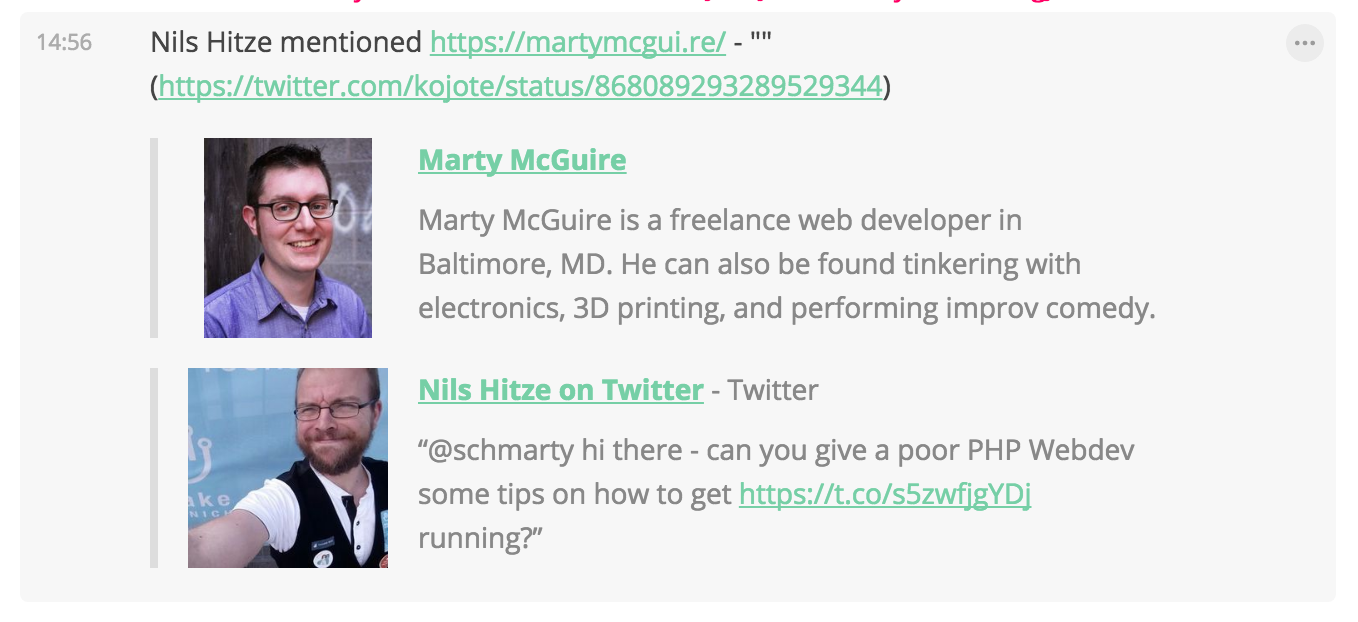
Notification example - a user on Twitter mentioned my Twitter handle in a post there.
I don't know how useful hubot-webmentionio-notify will be for other folks at the moment, but I am excited be getting these notifications via services that I control. I look forward to building more fun things with Hubot!
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
Below are notes from the "broadcast" portion of the meetup.
jonathanprozzi.net - not been making his weekly posts in challenges with Marty. Inspired by a nearby bookstore closing, realized he had done lots of learning in bookstores over the last ~15 years. New idea for a series of posts cataloging all the things learned in a specific place over the years. Wants to journal the things he is learning on a weekly(ish) basis to build an archive.
brianey.com - been writing up lots of ideas for his blog but not finishing them. Based on that unfinished work, started writing about some new topics on creativity. For example, writing about starting things vs. achieving them. Looking forward to writing those including cute graphics of badgers, (em)barkers, etc. and being inspired by those posts to take on other unfinished posts.
amyhurst.com - working on an FAQ page for all the questions she gets from students seeking to get into the grad programs that she manages. It should be a useful resource for students, but also for her to copy and paste into emails from students who don't or won't read it.
martymcgui.re - brought a bunch of posts from an old blog into his site, including old comments from disqus. Did updates to site plumbing so he can add syndication to his posts after the fact with micropub updates, allowing him to get webmentions and notifications of interactions on Twitter, FB, etc via brid.gy without pulling out a laptop.
We talked about the upcoming 2017 IndieWeb Summit June 24th-25th in Portland, Oregon and discussed the indie RSVPs on the site. From there we ended up on Aaron Parecki's site and chatted about the amount of information that is collected and shared, what things we'd like to be collecting for review about ourselves, what things we're comfortable publishing.
Left-to-right: martymcgui.re, brianey.com, amyhurst.com, jonathanprozzi.net. Also: many air plants.
We hope that you'll join us for the next HWC Baltimore on May 31st at the Digital Harbor Foundation Tech Center!
Jonathan Prozzi and I have challenged one another to make a post about improving our websites once a week. This one should have gone up last week!
A few weeks ago I posted some thoughts about my IndieWeb setup called "Easier POSSE with Micropub Edits?" in which I wished for a tool that would let me take a given post from my site, syndicate it to silos like Twitter and Facebook (tweaking the content if I want), and updating the post on my site to show the links to those syndicated copies.
Why?
I failed to make at least one important thing clear in my original post – why do I care about syndication links? There are many reasons.
If I decide that a post should be syndicated to a silo, it's because I want it to reach the people who follow me there and, if that is true, I also want their interactions to come back to my site. So, in these ways, a post isn't "done" unless it is on my site, with syndicated copies on the silos I care about, and with syndication links for brid.gy to feed the interactions back.
Starting at the End
I decided to start by making my site's Micropub server support Micropub Source Content Queries and Micropub Updates. Any tool that helped automate syndication would need this plumbing to operate.
When implementing a new feature, it always helps to have something to test against. So, I went looking for a Micropub client which supported queries and edits. The test suite for Micropub at micropub.rocks includes a lovely implementation report grid, showing which Micropub clients support what features of the spec.
Of the clients listed, two of them were web-based and Open Source. I had played with and liked Inkstone in the past, but its edit features are currently considered a work-in-progress. So, I tried out Micropublish.net, and it was exactly what I was looking for.
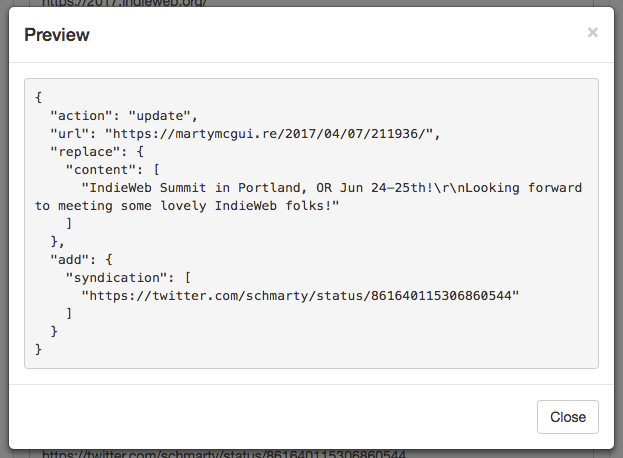
Micropublish has a feature to let you enter a URL for a post on your site to edit. It will use Micropub source content queries to get the source data for that post and let you edit the content and other properties of the post. It can then send a Micropub update to save the updated version of the post back to your site, if your server supports updates. It even has a great feature for developers - a "Preview" button will show you exactly what request will be sent to your server for the update.
Screenshot of micropublish.net preview for an update to add a syndication link to a post
Micropublish.net is a great tool for testing out Micropub query and update support, but my Micropub server is bespoke, hastily-written, hand-rolled Python. So, while it was easy enough to add query support, it took me a while to get my code structure cleaned up, write some tests, and actually implement updates.
A New Workflow
I am pleased to say that it works and, with the help of Micropublish.net, I now have a functioning workflow for publishing to my site and syndicating to silos like Twitter and Facebook, even from my phone, without having to open my laptop, edit YAML data, and push git repositories around. It looks like this.
Make a new post to my site with a micropub client like Quill.
Open the post for editing in micropublish.net (I use Url Forwarder for Android to make this super easy on my phone, a bookmarklet makes it easy on my laptop).
In a new tab, log in to Twitter and make a similar post, copy the URL to the new tweet into the Syndication field on my post.
Repeat the steps to make posts on Facebook, Mastodon, etc., copying their URLs into the Syndication field.
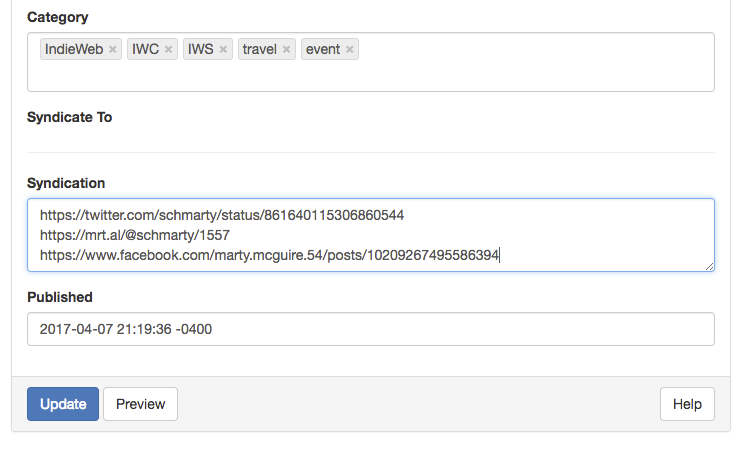
Finally, hit "Update" in micropublish.net to update my post with the syndication links.
Screenshot of micropublish.net with new syndication links
This is still a very manual process, but it now makes it possible to finish a post in a way that I couldn't before. In the spirit of manual until it hurts, I will use this for a while and see what existing pain points remain, and what new ones appear, to help decide what comes next.
Thanks to Barry Frost for micropublish.net and to Tantek for the nudge to write an update!
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!