Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
Rather than contradictions, these tensions are a source of inquiry, questions, and conversations.
Each could be expanded into their own discussion or exploration.
Each of them is an axis of sorts, with different “right” answers for different people, depending on what they want, and how much time or other resources they have.
Each makes the most sense when explored in the context of a focus on solving real user needs to participate directly on today’s web.
Each is also a trap for abstract logic, theoretical purity, or dogmatic absolutism, especially when detached from real world goals, constraints, and efforts.
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
Thanks to everyone in the IndieWeb chat for their feedback and suggestions. Please drop me a note if there are any changes you’d like to see for this audio edition!
tl;dr – Kapowski is a simplified tool for finding and posting reaction GIFs to your personal website. It works without a sign-in and gives you HTML to copy-paste into whatever posting interface you use for your website. It's "progressively enhanced" with IndieWeb building blocks, so if your site supports them it becomes faster and easier to use. Search and content are currently powered by Gfycat.
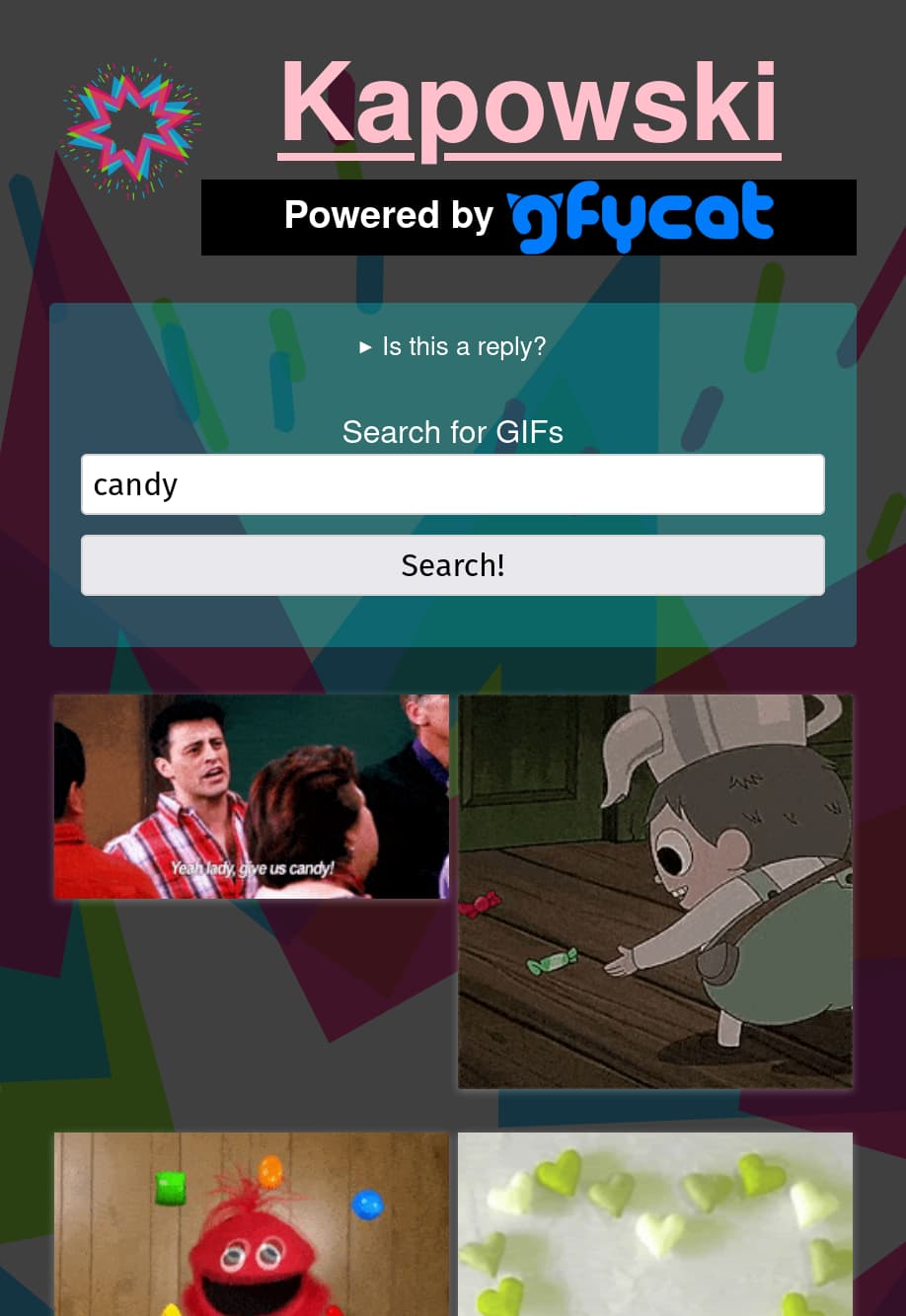
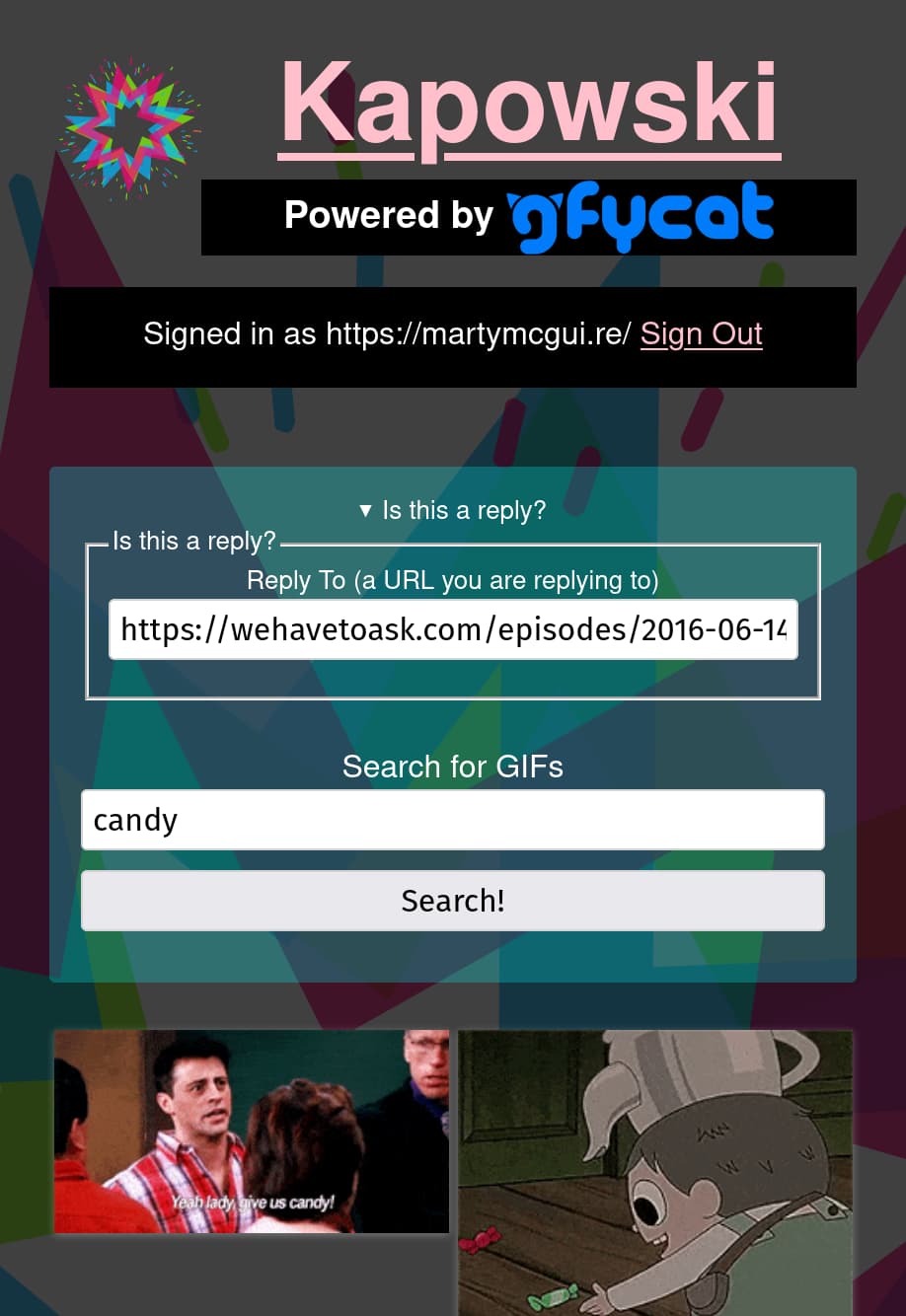
A Kapowski search for "candy"
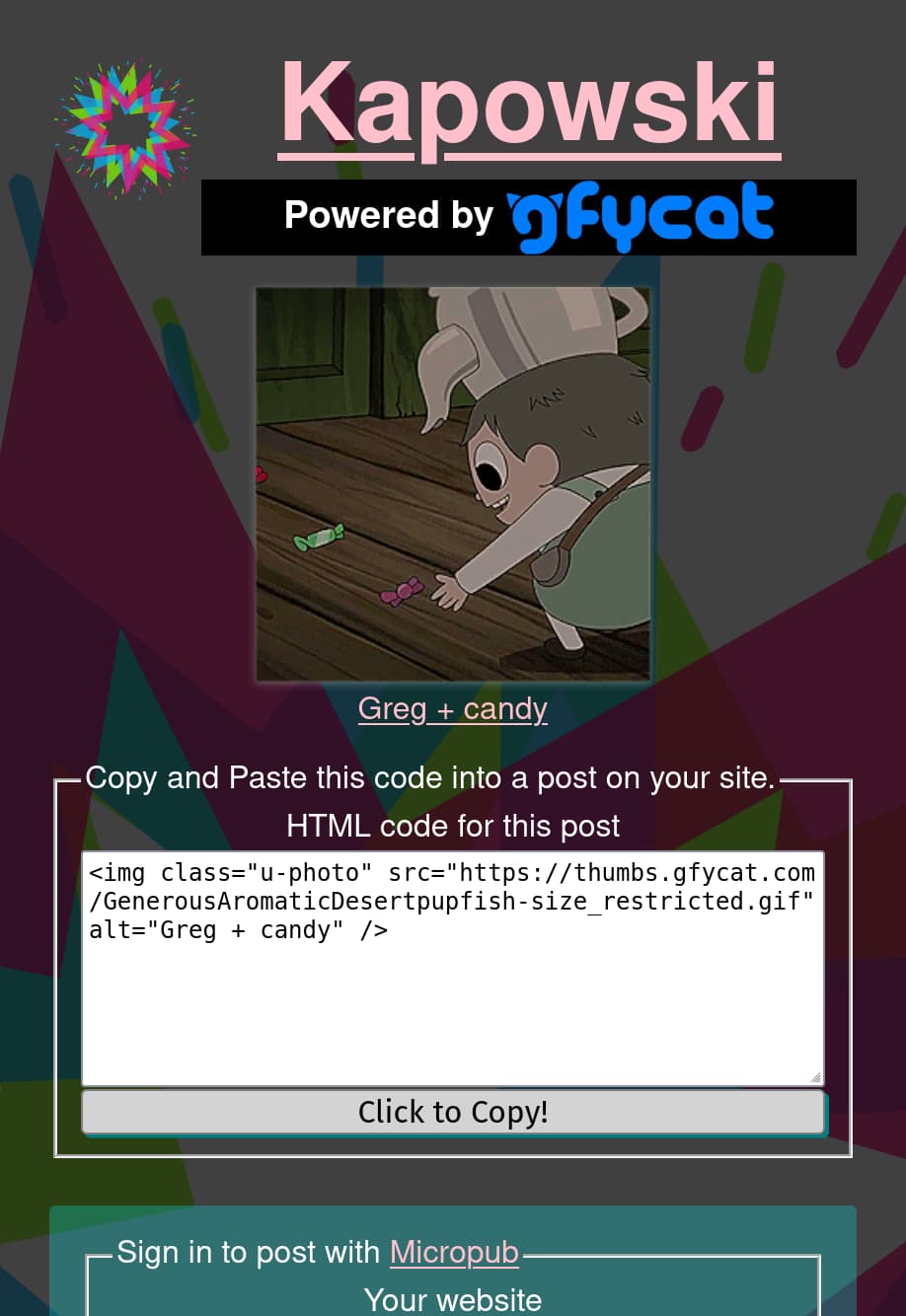
Preview of selected GIF with HTML source ready to copy-and-paste
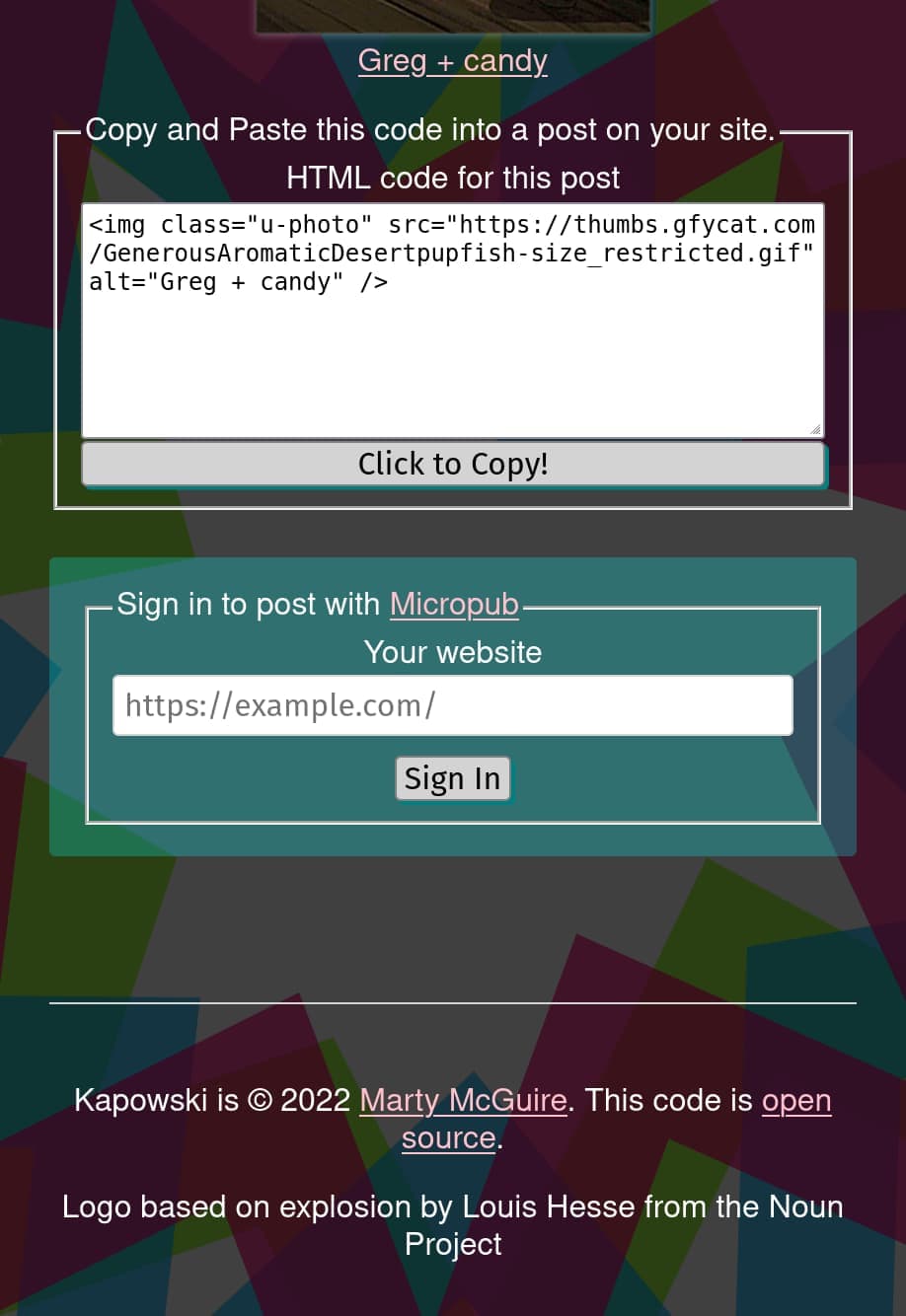
Kapowski supports IndieAuth and Micropub. If your site supports these, you can sign in using your website as your identity and then use Kapowski to post the image to your site directly.
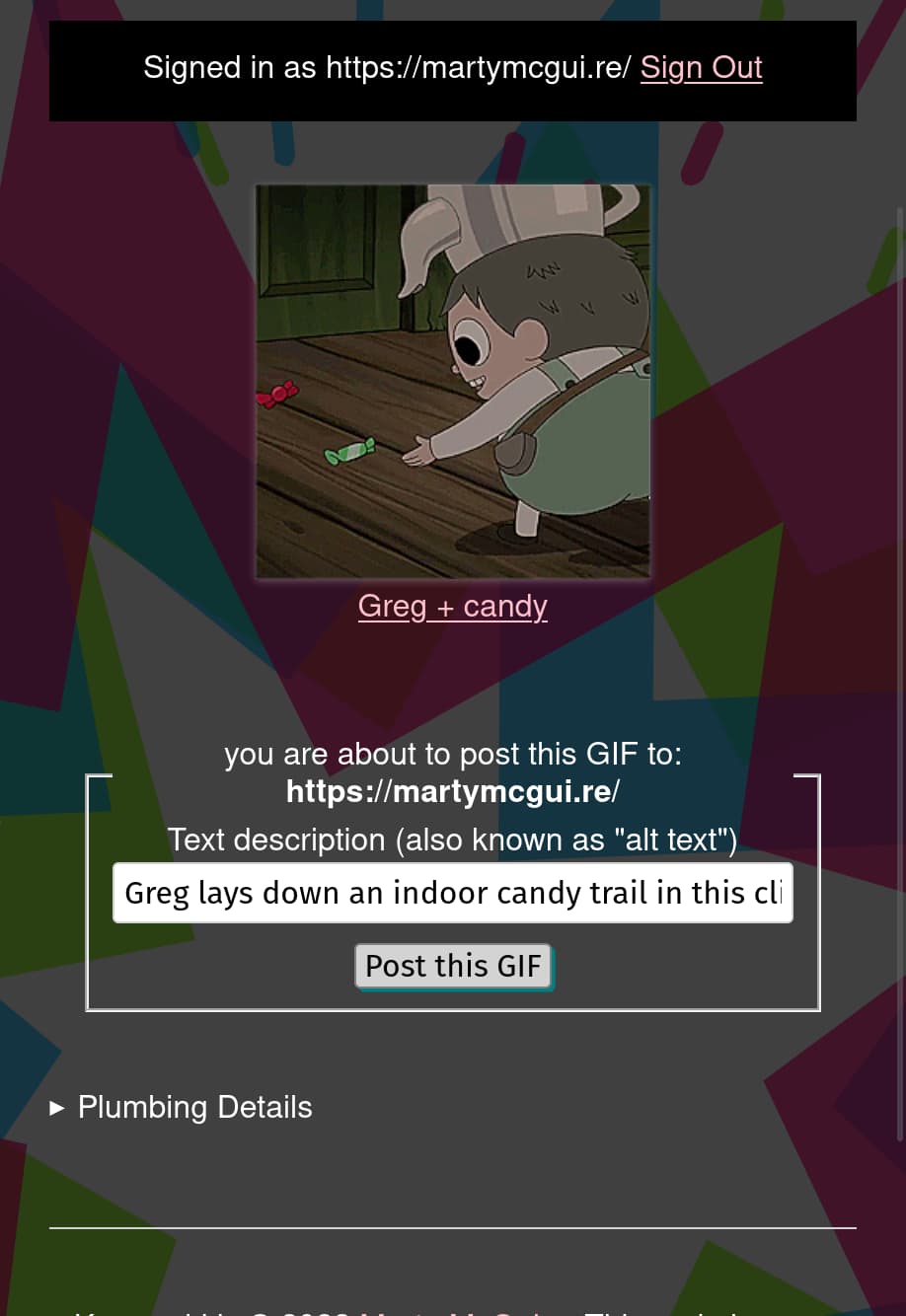
Preview page with sign-in formSigned in, alt-text entered, ready to post!
But that's not all! If your site supports sending Webmentions and markup for reply posts, you can use Kapowski to make your post a photo reply!
Search page with a URL in the optional reply fieldReply post on my site with context about the post I'm replying to.
Still reading? Here's some (too much) history.
I really like Micropub as an IndieWeb building block. As a developer, it's easy to understand on the wire. It's very extensible because the spec provides very few constraints over what you can post with it.
However, that flexibility comes at a coordination cost. I had (have!) a dream that being able to rapidly iterate on special-purpose Micropub clients will let many ways of posting bloom. I also loved (love!) Glitch as a place to build web apps in the open where other folk can see how they work and remix them to make them their own.
I kept Kapowski intentionally simple, hoping that some other IndieWeb folks might use it, give feedback, and iterate on the idea of what a good user experience might be for posting reply GIFs on the IndieWeb.
I ... didn't get much feedback! As far as I know, few people have used it. However, I very much did notice that it kept breaking.
Giphy, the original service Kapowski used, was bought by Facebook with the intention of, I don't know, tracking all the GIFs people posted. I didn't like that, so I switched things over to Gfycat. (Although with Facebook (Meta) being forced by UK regulators to sell off Giphy, maybe it'll be time soon to bring it back.)
The biggest problem, though, was that server-side Javascript bits rot. I want to be able to stand up a hobby project and forget it for months or years at a time. For a project of this pace, especially one that I think of as being very simple, the Javascript stack moves fast. I would get notices every week or so that this or that dependency had a required security update. Sometimes apply what looked like a small point update would cause a breaking change in an API (Axios!). Eventually, it became not-fun to think about keeping up Kapowski.
Multiplying this maintenance across a number of other Micropub clients I had managed to barely knock together on Glitch led to me burning out on the idea. So, I stopped maintaining it and at some point it stopped working.
Reviving the embers
I still want to see a thousand Micropub-powered flowers bloom, but I don't have the personal project bandwidth to build the tool set on Glitch that I thought would make that possible. I'm just not that fluent in server-side Javascript development and project management, and it's too far of a road right now to git gud.
That said, there are styles of web app development I am much more comfortable working in! I think I can take this stuff a lot further by sharpening the knives I already know how to use.
So, I've spent a good chunk of free time this year quietly porting some of my IndieWeb projects to PHP and hosting them on a virtual private server. That's stuff I know how to do! As I've re-built each one, I've also looked to extract the common points of similarity and complexity into a kind of "Micropub kit", with a common-but-extensible engine. That's made each client easier to build and deploy, and that's very exciting.
(This "micropub kit" isn't ready for public consumption at all but it is available for looking-at if you want. Here's the micropubkit source.)
What's next?
Since it's IndieWeb Gift Calendar season, I think I'll spend the next month polishing up and posting more about this work. If you have thoughts about Kapowski, "micropubkit", or posting weird stuff on the IndieWeb in general, I'd love to read them! Just reply to this post on your own site and send me a Webmention.