The hack is described in detail in that post, but basically:
use a <video> element instead of an <audio> element. make the <source> your audio (mp3 or whatever)
add a <track> element with your WebVTT subtitles
make sure to use a poster image so the video gets some space in the page
This has been broken for a few years, at least according to my notes, and I keep failing at finding a fix.
As of now:
Firefox no longer shows the “CC” control or options to enable captions
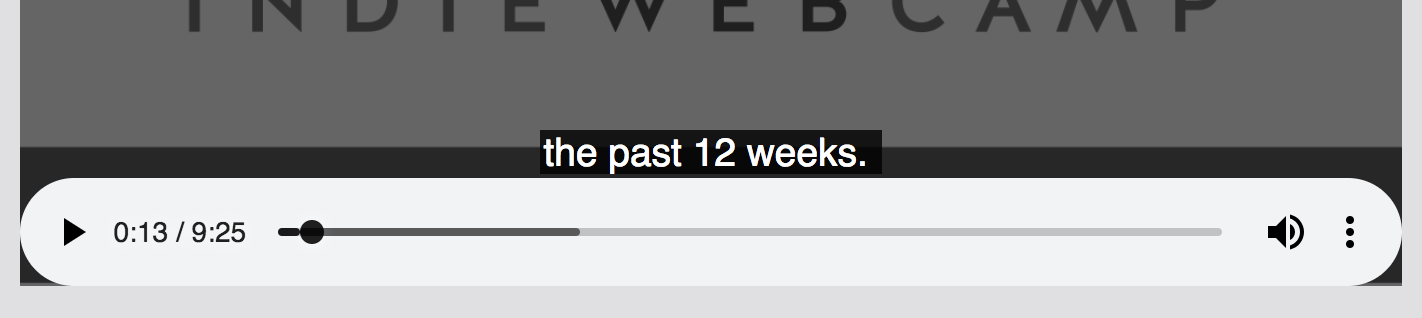
Chrome-based browsers show the captions, but you can’t see them because they are behind the media controls, which never seem to go away.
A screenshot of Chrome's media player controls where the timeline scrubber obscures the captions. We see one line reading "the past twelve weeks" peeking above the controls.
This post is me absolving myself of finding a fix for now! 🕊️
After the 2017 IndieWeb Summit, each episode of the podcast also featured a brief ~1 minute interview with one of the participants there. As a way of highlighting these interviews outside the podcast itself, I became interested in the idea of "audiograms" – videos that are primarily audio content for sharing on platforms like Twitter and Facebook. I wrote up my first steps into audiograms using WNYC's audiogram generator.
While these audiograms were able to show visually interesting dynamic elements like waveforms or graphic equalizer data, I thought it would be more interesting to include subtitles from the interviews in the videos. I learned that Facebook supports captions in a common format called SRT. However, Twitter's video offerings have no support for captions.
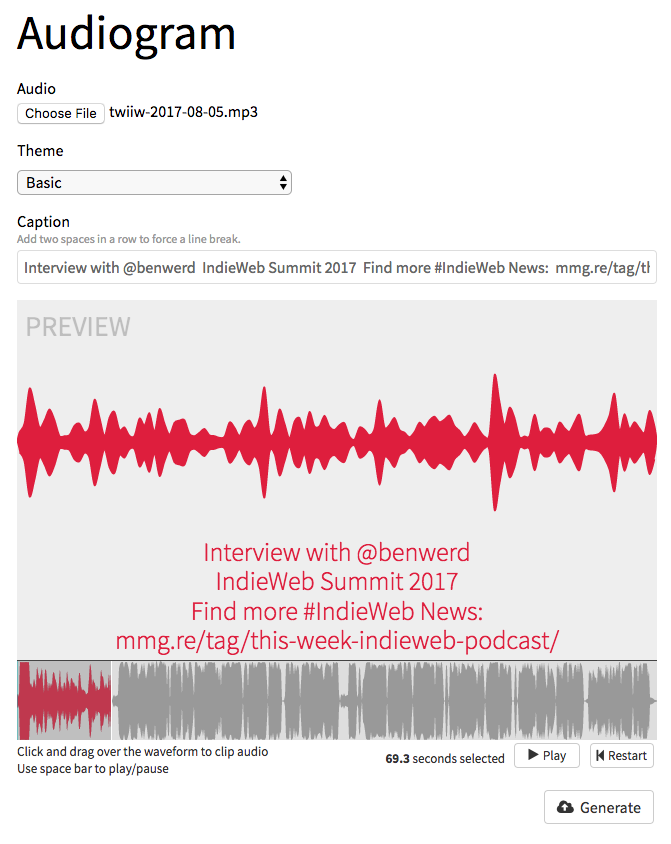
Thankfully, I discovered the BBC's open source fork of audiogram, which supports subtitles and captioning, including the ability to "bake in" subtitles by encoding the words directly into the video frames. It also relies heavily on BBC web infrastructure, and required quite a bit of hacking up to work with what I had available.
The BBC Audiogram captioning interface.
In the end, my process looked like this:
Export the audio of the ~1 minute interview to an mp3.
Type up a text transcript of the audio. Using VLC's playback controls and turning the speed down to 0.33 made this pretty easy.
Use a "forced alignment" tool called gentle to create a big JSON data file containing all the utterances and their timestamps.
Use the jq command line tool to munge that JSON data into a format that my hacked-up version of the BBC audiogram generator can understand.
Use the BBC audiogram generator to edit the timings and word groupings for the subtitles and generate the final video.
Bonus: the BBC audiogram generator can output subtitles in SRT format - but if I've already "baked them in" this feels redundant.
You can see an early example here. I liked these posts and found them easy to post to my site as well as Facebook, Twitter, Mastodon, etc. Over time I evolved them a bit to include more info about the interviewee. Here's a later example.
One thing that has stuck with me is the idea that Facebook could be displaying these subtitles, if only I was exporting them in the SRT format. Additionally, I had done some research into subtitles for HTML5 video with WebVTT and the <track> element and wondered if it could work for audio content with some "tricks".
TL;DR - Browsers will show captions for audio if you pretend it is a video
Let's skip to the end and see what we're talking about. I wanted to make a version of my podcast where the entire ~10 minutes could be listened to along with timed subtitles, without creating a 10-minute long video. And I did!
How does it work? Well, browsers aren't actually too picky about the data types of the <source> elements inside. You can absolutely give them an audio source.
Add in a poster attribute to the <video> element, and you can give the appearance of a "real" video.
And finally, add in the <source> element with your subtitle track and you are good to go.
The relevant source for my example post looks something like this:
Use the <track> element for your captions/subtitles/etc.
But is that the whole story? Sadly, no.
Creating Subtitles/Captions in WebVTT Format
In some ways, This Week in the IndieWeb Audio Edition is perfectly suited for automated captioning. In order to keep it short, I spend a good amount of time summarizing the newsletter into a concise script, which I read almost verbatim. I typically end up including the transcript when I post the podcast, hidden inside a <details> element.
This script can be fed into gentle, along with the audio, to find all the alignments - but then I have a bunch of JSON data that is not particularly useful to the browser or even Facebook's player.
Thankfully, as I mentioned above, the BBC audiogram generator can output a Facebook-flavored SRT file, and that is pretty close.
00:00:02,24 --> 00:00:04,77
While at the 2017 IndieWeb Summit,
00:00:04,84 --> 00:00:07,07
I sat down with some of the
participants to ask:
Into this:
WEBVTT
00:00:02.240 --> 00:00:04.770
While at the 2017 IndieWeb Summit,
00:00:04.840 --> 00:00:07.070
I sat down with some of the
participants to ask:
Yep. When stripped down to the minimum, the only real differences in these formats is the time format. Decimals delimit subsecond time offsets (instead of commas), and three digits of precision instead of two. Ha!
The Future
If you've been following the podcast, you may have noticed that I have not started doing this for every episode.
The primary reason is that the BBC audiogram tool becomes verrrrry sluggish when working with a 10-minute long transcript. Editing the timings for my test post took the better part of an hour before I had an SRT file I was happy with. I think I could streamline the process by editing the existing text transcript into "caption-sized" chunks, and write a bit of code that will use the pre-chunked text file and the word-timings from gentle to directly create SRT and WebVTT files.
Additionally, I'd like to make these tools more widely available to other folks. My current workflow to get gentle's output into the BBC audiogram tool is an ugly hack, but I believe I could make it as "easy" as making sure that gentle is running in the background when you run the audiogram generator.
Beyond the technical aspects, I am excited about this as a way to add extra visual interest to, and potentially increase listener comprehension for, these short audio posts. There are folks doing lots of interesting things with audio, such as the folks at Gretta, who are doing "live transcripts" with a sort of dual navigation mode where you can click on a paragraph to jump the audio around and click on the audio timeline and the transcript highlights the right spot. Here's an example of what I mean.
I don't know what I'll end up doing with this next, but I'm interested in feedback! Let me know what you think!
Enter the Audiogram Generator, an open source project that runs on NodeJS and uses FFMPEG to take samples from your audio files and munge them into short videos for sharing on social networks.
Here's a quick rundown of how I got the Audiogram Generator running on my macOS laptop using Docker.
I use Homebrew, so first I installed docker and docker-machine and created a new default machine:
I don't yet know exactly how I'll choose what portions to share on each silo, what text and links to accompany them to encourage folks to listen to the full episodes, and so on. There are also some quirks to learn. For example, Twitter has a maximum length of 2:20 for videos, and its cropping tool would glitch out and reset to defaults unless I stopped it "near" the end.
Thankfully, there is a very detailed Audiogram Generator usage doc with lots of examples and guidelines for making attention-getting posts.
For the near term I want to play with the tool to see what kinds of results I can make. Long-term I think this would be a really neat addition to my Screech tool, which is designed for posting audio to your own website.
How do you feel about audiograms? I'd love to hear other folks' thoughts!