Syndicating Audio Posts with WNYC's Audiogram Generator
I publish a few different podcasts and often find myself advertising new episodes by syndicating new posts to various social media silos.
Sadly, few social media services consider audio to be "a thing", despite often having robust support for video.
I'm certainly not the first person to notice this, and the fine folks at WNYC have taken this audio sharing problem head-on.
Enter the Audiogram Generator, an open source project that runs on NodeJS and uses FFMPEG to take samples from your audio files and munge them into short videos for sharing on social networks.
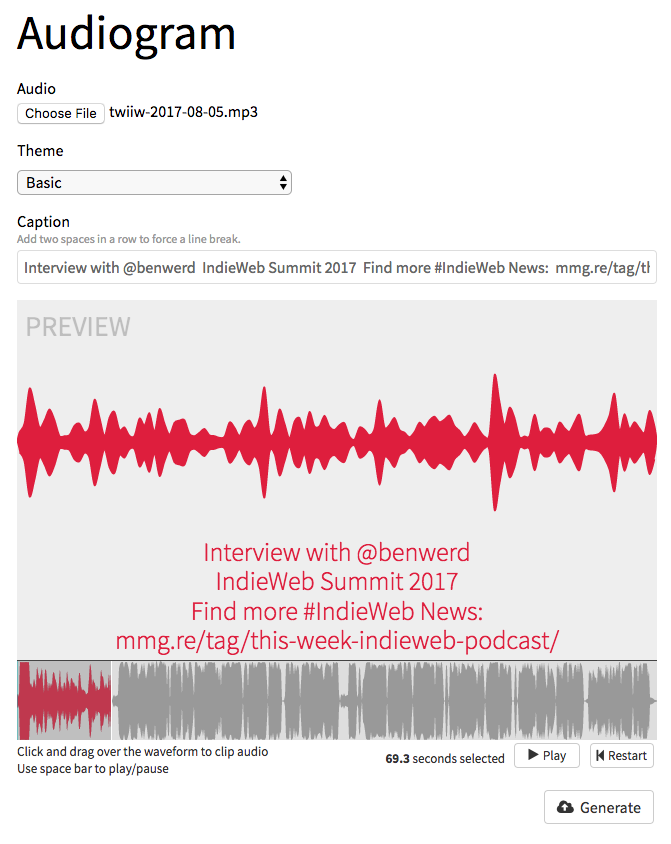
Here's a quick rundown of how I got the Audiogram Generator running on my macOS laptop using Docker.
I use Homebrew, so first I installed docker and docker-machine and created a new default machine:
brew install docker docker-machine docker-machine create -d virtualbox default
Once that finished, I set my environment variables so the docker command line utility can talk to this machine:
eval $(docker-machine env)
Next, it was time to download the source for the audiogram generator from GitHub and build the Docker container for it:
git clone https://github.com/nypublicradio/audiogram.git cd audiogram docker build -t audiogram .
Finally, I could run it:
docker run -p 8888:8888 -t -i audiogram npm start
Once up, I pointed my browser at http://192.168.99.100:8888/ and I saw pretty much the interface that you see in the screenshot above.
The basic usage steps are:
- Choose an audio file
-
Choose a template
- Templates w/ images are hardcoded into the app, so if you want to use them with your own images you'll have to make changes to the source.
- Choose a selection of the audio that is less than 300 seconds long
- Add any text if the template requires it
- Generate!
- Download
- Upload to silos!
I made a sample post to my own site using a selection of an interview and then syndicated that post by uploading the same video to Twitter, Facebook, and Mastodon.
I don't yet know exactly how I'll choose what portions to share on each silo, what text and links to accompany them to encourage folks to listen to the full episodes, and so on. There are also some quirks to learn. For example, Twitter has a maximum length of 2:20 for videos, and its cropping tool would glitch out and reset to defaults unless I stopped it "near" the end.
Thankfully, there is a very detailed Audiogram Generator usage doc with lots of examples and guidelines for making attention-getting posts.
For the near term I want to play with the tool to see what kinds of results I can make. Long-term I think this would be a really neat addition to my Screech tool, which is designed for posting audio to your own website.
How do you feel about audiograms? I'd love to hear other folks' thoughts!